[Python] 네이버 뉴스 기사 웹 크롤링 - 매크로
해당 사이트를 참고하여 게시글을 작성하였습니다.
1단계. 원하는 웹 페이지의 html문서를 싹 긁어온다.
2단계. 긁어온 html 문서를 파싱(Parsing)한다.
3단계. 파싱한 html 문서에서 원하는 것을 골라서 사용한다.
https://sillon-coding.tistory.com/301
[Python] 뉴스의 제목, 날짜, 본문 데이터 가져오기 - 1회성 (매크로아님)
target_url 변수에 해당 링크를 입력하면 됩니다. from urllib.request import urlopen from bs4 import BeautifulSoup news_info = {"title": "", "content": "", "data": "" } def news_content_crawl(target_ur..
sillon-coding.tistory.com
저는 기존에 뉴스 기사 링크를 입력하면 해당 링크의 뉴스기사를 받아올 수 있는 코드를 짠 적이 있습니다. 해당 코드를 바탕으로 위의 문서를 참고하여 1회성 코드를 매크로로 만들어보겠습니다.
이번에는 target_url에 네이버 뉴스 정치 분야의 링크를 받아오고, 링크에서 받은 각 뉴스 헤드라인을 수집하여 각각의 url에 들어가, 해당 뉴스 기사를 크롤링해오도록 하겠습니다.
구현을 위해 이전의 코드와는 다르게 구성하였습니다.
틀만 바꾼 코드
from urllib.request import urlopen
from bs4 import BeautifulSoup
title = []
content = []
data = []
def news_content_crawl(url):
html = urlopen(target_url)
bsObject = BeautifulSoup(html, "html.parser")
title_it = bsObject.find("div", {"class":"media_end_head_title"}).get_text()
content_it = bsObject.find("div", {"class":"go_trans _article_content"}).get_text()
date_it = bsObject.find("span", {"class":"media_end_head_info_datestamp_time _ARTICLE_DATE_TIME"}).get_text()
for c in content_it:
c = c.replace("\n","")
title.append(title_it)
content.append(content_it)
data.append(date_it)
def news_list(target_url):
if __name__ =="__main__":
target_url = "https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100"
news_content_crawl(target_url)
news_list 를 통해서 매크로를 구현해보도록 하겠습니다.
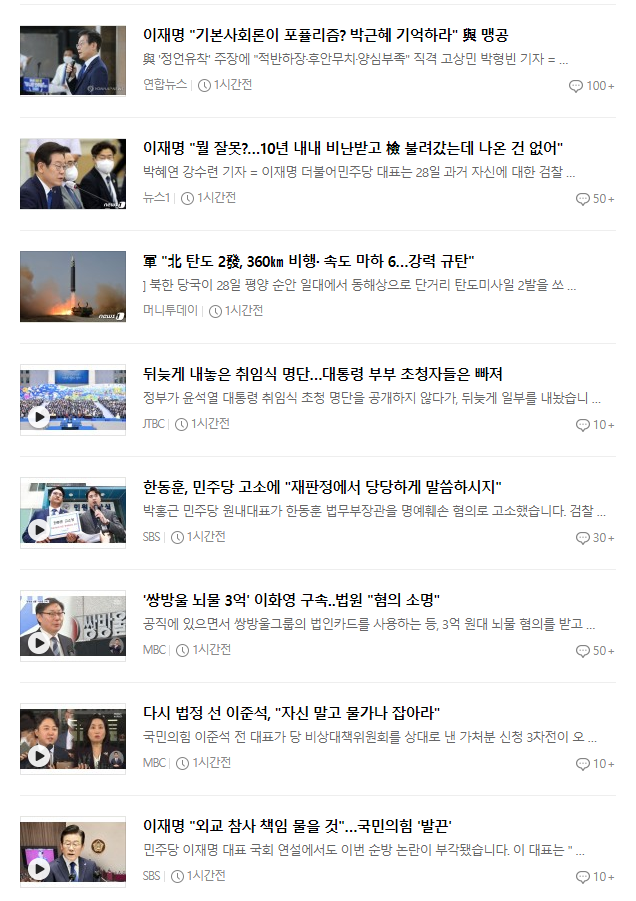
해당 사이트에 들어가면 위에 헤드라인 뉴스가 보입니다.
저는 헤드라인 뉴스가 아닌 밑에있는 기사들을 크롤링 할 것입니다.

from urllib.request import urlopen
from bs4 import BeautifulSoup
import requests
title = []
content = []
date = []
def news_content_crawl(url):
html = urlopen(url)
bsObject = BeautifulSoup(html, "html.parser")
title_it = bsObject.find("div", {"class":"media_end_head_title"}).get_text()
content_it = bsObject.find("div", {"class":"go_trans _article_content"}).get_text()
date_it = bsObject.find("span", {"class":"media_end_head_info_datestamp_time _ARTICLE_DATE_TIME"}).get_text()
for c in content_it:
c = c.replace("\n","")
title.append(title_it)
content.append(content_it)
date.append(date_it)
def get_href(target_url,soup):
# soup 객체에서 추출해야 하는 정보를 찾고 반환
# 상위 페이지에서의 href를 찾아 리스트로 반환
div = soup.find("div", class_="list_body section_index")
result = []
for a in div.find_all("a", class_="news"):
result.append(target_url + a["href"])
return result
def news_list(target_url):
list_href = []
list_content = []
req = requests.get(target_url)
soup = BeautifulSoup(req.text, "html.parser")
list_href = get_href(target_url,soup)
print(list_href)
for url in list_href:
href_req = requests.get(target_url)
href_soup = BeautifulSoup(href_req.text, "html.parser")
news_content_crawl(href_soup)
print(title)
print()
print(content)
print()
print(date)
if __name__ =="__main__":
target_url = "https://n.news.naver.com/mnews/article/082/0001176080?sid=100"
news_list(target_url)근데 결과가 와이라노?
