Project/캡스톤디자인2
[NLP Project] Padding , Attention mask
sillon
2022. 11. 11. 09:58
728x90
반응형
pickle file save & load

main.py
import pickle
import numpy as np
def file_open(filePath):
f =open(filePath,"rb")
data = pickle.load(f)
f.close()
return data
if __name__ == "__main__":
tokened_data = file_open('data/token_data.pkl')
tokenized_texts = [token_label_pair[0] for token_label_pair in tokened_data]
labels = [token_label_pair[1] for token_label_pair in tokened_data]
## padding
print(np.quantile(np.array([len(x) for x in tokenized_texts]), 0.975))
max_len = 88
bs = 32문장의 길이가 상위 2.5%(88) 인 지점을 기준으로 문장의 길이를 정하도록 하겠습니다.
만약 문장의 길이가 88보다 크면 문장이 잘리게 되고, 길이가 88보다 작다면 패딩이 되어 모든 문장의 길이가 88로 정해지게 됩니다.
print(np.quantile(np.array([len(x) for x in tokenized_texts]), 0.975))출 력
96.0
버트에 인풋으로 들어갈 train 데이터를 만들도록 하겠습니다.
버트 인풋으로는
input_ids : 문장이 토크나이즈 된 것이 숫자로 바뀐 것,
attention_masks : 문장이 토크나이즈 된 것 중에서 패딩이 아닌 부분은 1, 패딩인 부분은 0으로 마스킹
[input_ids, attention_masks]가 인풋으로 들어갑니다.
Padding
import pickle
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer
def file_open(filePath):
f =open(filePath,"rb")
data = pickle.load(f)
f.close()
return data
if __name__ == "__main__":
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
tokened_data = file_open('data/token_data.pkl')
tokenized_texts = [token_label_pair[0] for token_label_pair in tokened_data]
labels = [token_label_pair[1] for token_label_pair in tokened_data]
## padding
print(np.quantile(np.array([len(x) for x in tokenized_texts]), 0.975))
max_len = 88
bs = 32
input_ids = pad_sequences([tokenizer.convert_tokens_to_ids(txt) for txt in tokenized_texts],
maxlen=max_len, dtype = "int", value=tokenizer.convert_tokens_to_ids("[PAD]"), truncating="post", padding="post")
print(input_ids[0])

input_text, input tags Padding
## padding
print(np.quantile(np.array([len(x) for x in tokenized_texts]), 0.975))
max_len = 88
bs = 32
input_ids = pad_sequences([tokenizer.convert_tokens_to_ids(txt) for txt in tokenized_texts],
maxlen=max_len, dtype = "int", value=tokenizer.convert_tokens_to_ids("[PAD]"), truncating="post", padding="post")
label_dict = {'PER_B': 0, 'DAT_B': 1, '-': 2, 'ORG_B': 3, 'CVL_B': 4, 'NUM_B': 5, 'LOC_B': 6, 'EVT_B': 7, 'TRM_B': 8, 'TRM_I': 9, 'EVT_I': 10, 'PER_I': 11, 'CVL_I': 12, 'NUM_I': 13, 'TIM_B': 14, 'TIM_I': 15, 'ORG_I': 16, 'DAT_I': 17, 'ANM_B': 18, 'MAT_B': 19, 'MAT_I': 20, 'AFW_B': 21, 'FLD_B': 22, 'LOC_I': 23, 'AFW_I': 24, 'PLT_B': 25, 'FLD_I': 26, 'ANM_I': 27, 'PLT_I': 28, '[PAD]': 29}
tags = pad_sequences([lab for lab in labels], maxlen=max_len, value=label_dict["[PAD]"], padding='post',\
dtype='int', truncating='post')
print(input_ids[0])
print(tags[0])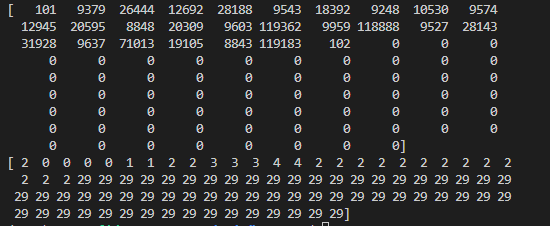
어텐션 마스크를 만들어 주겠습니다.
attention_masks = np.array([[int(i != tokenizer.convert_tokens_to_ids("[PAD]")) for i in ii] for ii in input_ids])
import pickle
import numpy as np
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer
def file_open(filePath):
f =open(filePath,"rb")
data = pickle.load(f)
f.close()
return data
if __name__ == "__main__":
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
tokened_data = file_open('data/token_data.pkl')
tokenized_texts = [token_label_pair[0] for token_label_pair in tokened_data]
labels = [token_label_pair[1] for token_label_pair in tokened_data]
## padding
# print(np.quantile(np.array([len(x) for x in tokenized_texts]), 0.975))
max_len = 88
bs = 32
input_ids = pad_sequences([tokenizer.convert_tokens_to_ids(txt) for txt in tokenized_texts],
maxlen=max_len, dtype = "int", value=tokenizer.convert_tokens_to_ids("[PAD]"), truncating="post", padding="post")
label_dict = {'PER_B': 0, 'DAT_B': 1, '-': 2, 'ORG_B': 3, 'CVL_B': 4, 'NUM_B': 5, 'LOC_B': 6, 'EVT_B': 7, 'TRM_B': 8, 'TRM_I': 9, 'EVT_I': 10, 'PER_I': 11, 'CVL_I': 12, 'NUM_I': 13, 'TIM_B': 14, 'TIM_I': 15, 'ORG_I': 16, 'DAT_I': 17, 'ANM_B': 18, 'MAT_B': 19, 'MAT_I': 20, 'AFW_B': 21, 'FLD_B': 22, 'LOC_I': 23, 'AFW_I': 24, 'PLT_B': 25, 'FLD_I': 26, 'ANM_I': 27, 'PLT_I': 28, '[PAD]': 29}
tags = pad_sequences([lab for lab in labels], maxlen=max_len, value=label_dict["[PAD]"], padding='post',\
dtype='int', truncating='post')
# Attention mask
attention_masks = np.array([[int(i != tokenizer.convert_tokens_to_ids("[PAD]")) for i in ii] for ii in input_ids])
print(attention_masks[0])[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0]
728x90
반응형