이 게시글은 김성범 교수님의 유튜브 강의를 정리한 내용입니다.
내용과 사진의 각 출처는 김성범 교수님께 있음을 미리 알립니다.
해당 게시글 강의 영상: https://www.youtube.com/watch?v=GciPwN2cde4&list=PLpIPLT0Pf7IoTxTCi2MEQ94MZnHaxrP0j&index=10

Boosting 알고리즘 종류
- Adaptive boosting (Adaboost)
- Gradient boosting machines (GBM)
- XGboost
- Light gradient boost machines (Light GBM)
- Catboost
AdaBoost
- 각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보완
- Training error 가 큰 관측치의 선택 확률(가중치)를 높이고, training error가 작은 관측치의 선택 확률을 낮춤
- 오분류한 관측치에 보다 집중
- 앞 단계에서 조정된 확률(가중치)을 기반으로 다음 단계에서 사용될 training dataset를 구성
- 다시 첫 단계로 감
- 최종 결과물은 각 모델의 성능지표를 가중치로 하여 결합(앙상블)

h: model. 분류기(classifier)
I(A) : if A true -> 1
if A false -> 0



함수를 그려보면 0.5에서 0으로 떨어지고, 0이나 1로갈 때 알파는 큰 값이 된다.
loss Function = 0.5 라는 것은 알파가 0이라는 것이다.
반밖에 못맞추었다 -> 매우 헷갈린 경우
loss Function = 0 - > 알파가 크다(무한대) -> perfect

- 첫번째 스탭: 가중치를 줄 때 1/n으로 주겠다.
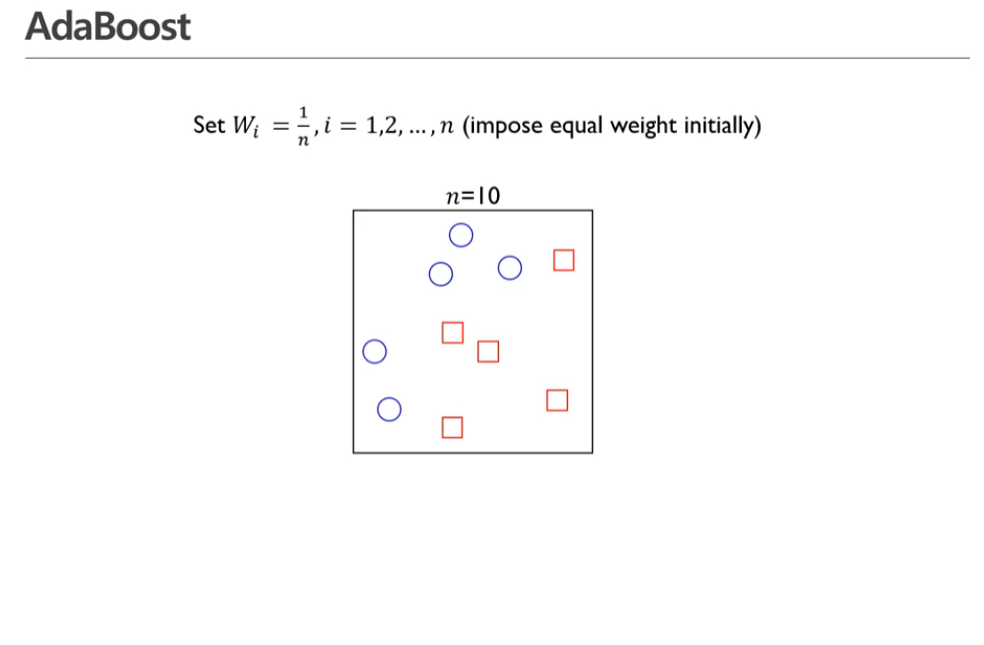
n = 10, 따라서 가중치 w = 0.1 로 준다.

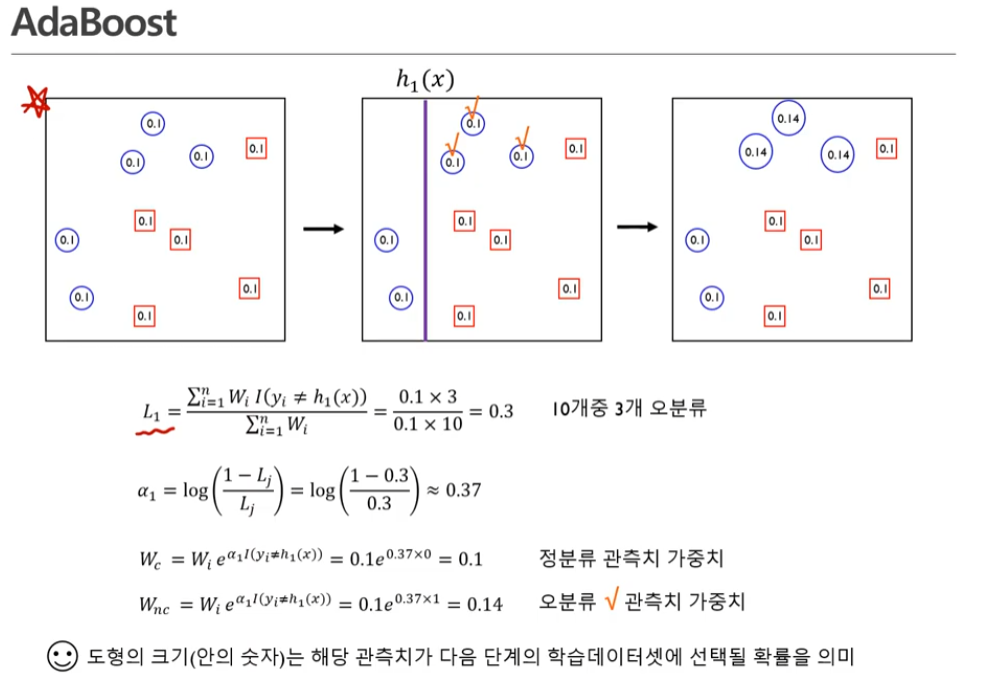
Boosting 에서 많이 쓰이는 베이스 모델은 Decision Tree 이다.
분모: 모든 가중치에대한 가중 합

분자: indicate function
실제 y값과 모델로부터 나온 레이블이 다를 때만 1이 된다. -> 다른 값이 3개이니까 3임
즉, 정분류한 것은 고려하지않고 오분류한것만 고려함

정분류한 관측치의 가중치는 변하지 않는다.
오분류한 관측치의 가중치는 변하게 된다!!
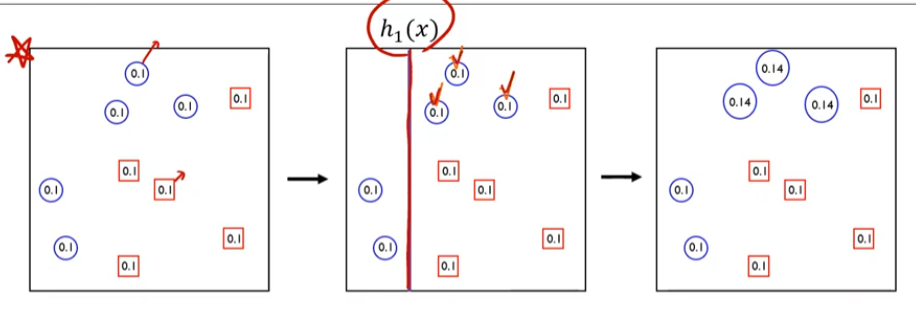
- 두번째 스텝:
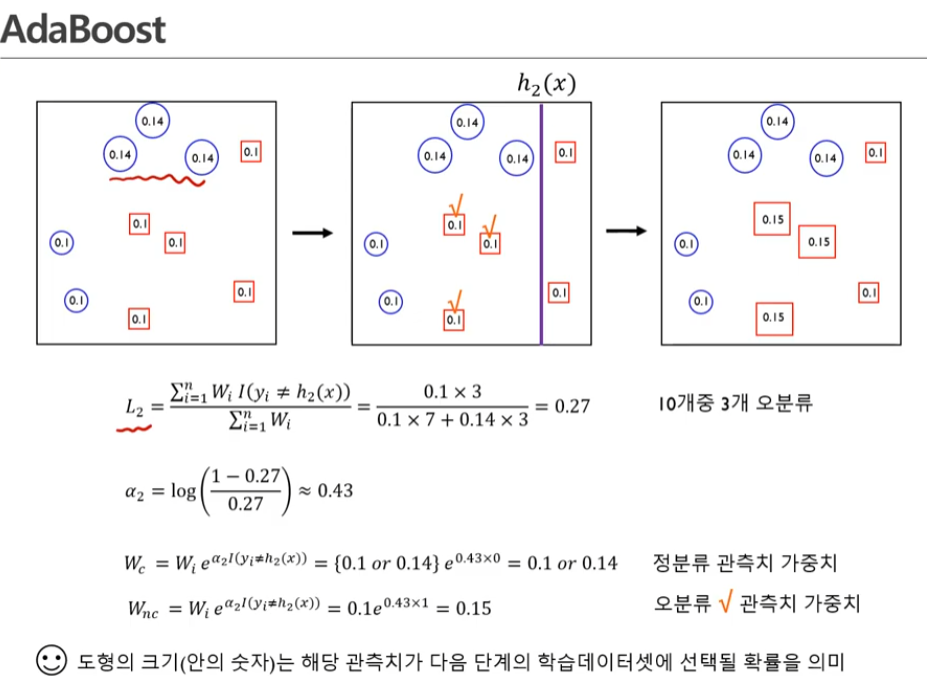
오분류 된 것은 여기 있는 네모들..

두번째 classcifier 관측치 0.43 (알파값임)


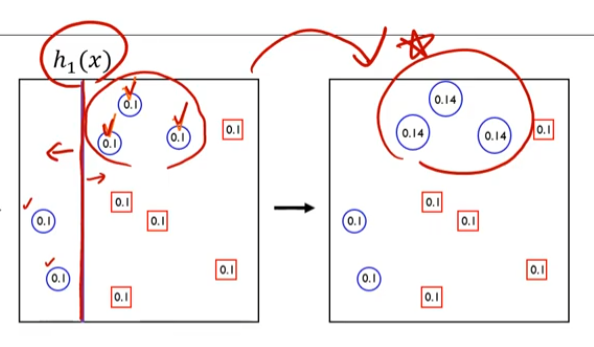
- 세번째 단계
그 결과를 갖고 세번째 classfier를 구축

세번째 단계까지 가면 0.1 이었던 가중치가 0.16로 바뀌게 됩니다
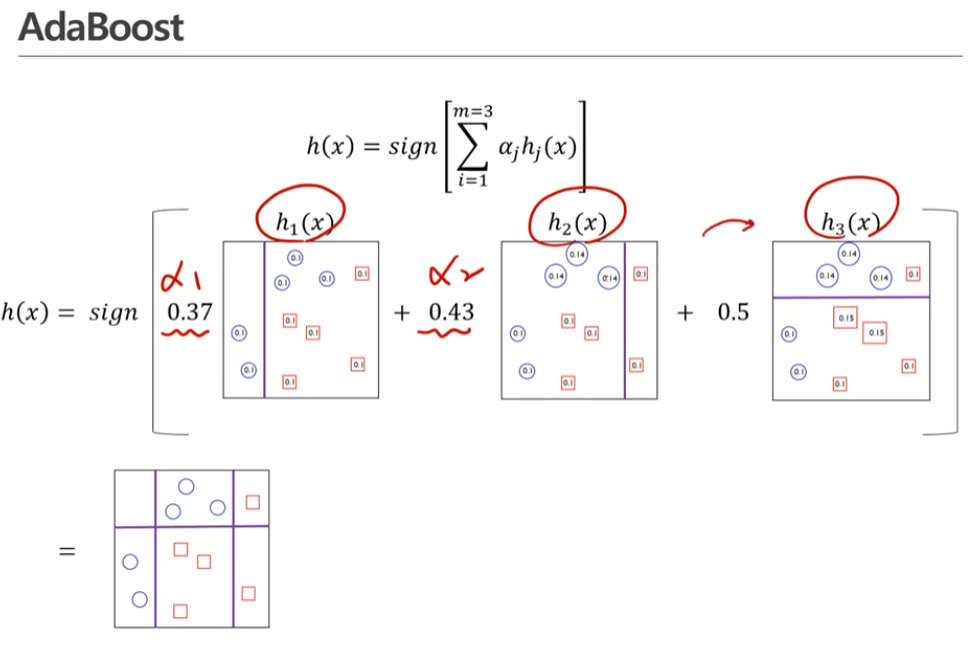
이 세개 단계를 거쳤던 것을 모아서 하나의 모델을 만든다! ^^
세개의 classifier에 의하면 perfect한 classfier가 생길 수 있다.

다시한번 정리해보면
두번째 과정은 이제 우리가 오분류한 관측치에 중점을 두겠다는 것이다.
classifier

이런 식으로 순차적으로 모델을 구축하는 방법이라고 할 수 있다.

 |
 |
 |
| 하나의 트레인 데이터로 모델로 만드는 것 |
하나의 트레인 셋으로 Bootstrab을 통해 여러개의 샘플을 만든다 (랜덤포레스트의 아이디어) |
하나의 트레인 셋이 있으면 그것에 해당하는 모델을 만들어 가중치를 업데이트 해당 과정을 반복하여 마지막에 더함 |
Gradient Boosting Machines (GBM)

베이스 모델: 결정 트리(decision Tree)
residual: 예측값과 실제값의 차이 (오차)
세개의 트리 값을 더하면 최종적인 트리모델 완성
 |
 |
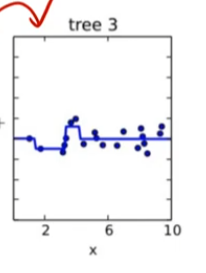 |
| 트리모델을 이용해서 데이터를 pick 한 것 | 첫번째 트리모델에서 y값과의 차이 첫번째 트리로 부터 나온 값에서 residual을 구한 값 |
두번째 나온 트리에서의 residual |

왜 gradient라고 불렀는가?
미분이라고 생각하면 된다.
MSE를 미분하면

f(x)에 대하여 미분한다.
실제 y와 예측값 f(x)


사실은 residual boosting machine 하는게 직관적이지만 간지나게 그라디언트라고 했음
결국 핵심은 residual


이렇게 계속 이어지는 것이담

대충 M개의 decision tree
residual 을 계속해서 진행하면서 트리를 업데이트해나감

빨간색 선은 decision tree 모델로 나온 결괏값임
초록색 점은 빨간색 점과 파란색 점의 차이 (residual value)
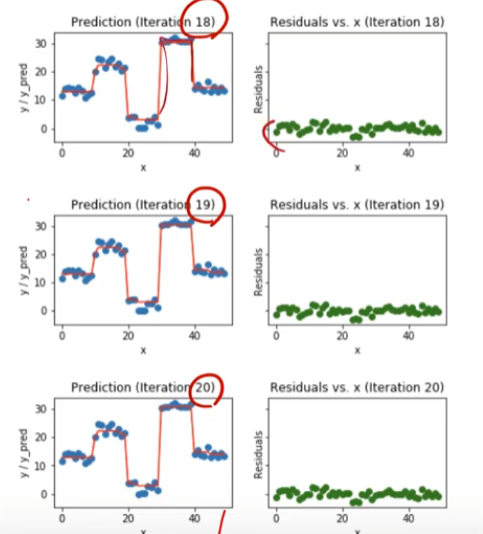
점점 모델이 정교해진다
알고리즘:
문제를 해결하기위한 방법론들의 집합
알고리즘이 나왔을 때 이해하려고 노력한다
이해가 안되면 체크함
그리고 알고리즘을 설명하는 예제나 그림을 찾아본다..
모델도 비슷하게 공부하면 ㅗ딘다

여기서 나오는 수식은 즉 residual 값

'공부정리 > Deep learnig & Machine learning' 카테고리의 다른 글
| [딥러닝] 활성화 함수 요약 정리 (0) | 2022.08.22 |
|---|---|
| [핵심 머신러닝] 군집분석 (0) | 2022.08.17 |
| [핵심 머신러닝] 뉴럴네트워크모델 2 (Backpropagation 알고리즘) (0) | 2022.08.12 |
| [핵심 머신러닝]뉴럴네트워크모델 1 (구조, 비용함수, 경사하강법) (0) | 2022.08.12 |
| [핵심 머신러닝] 랜덤포레스트 모델 (0) | 2022.08.11 |