손실 함수(loss function) 란?
- 머신러닝 혹은 딥러닝 모델의 출력값과 사용자가 원하는 출력값의 오차를 의미
- 손실함수는 정답(y)와 예측(^y)를 입력으로 받아 실숫값 점수를 만드는데, 이 점수가 높을수록 모델이 안좋은 것
- 손실함수의 함수값이 최소화 되도록 하는 가중치(weight)와 편향(bias)를 찾는 것이 목표
1. binary_crossentropy (이항 교차 엔트로피)
- y값이 (ex. 0,1) 인 이진 분류기를 훈련할 때 자주 사용되는 손실 함수 (multi-label classification)
- 활성화 함수 : sigmoid 사용 (출력값이 0과 1사이의 값)
- 수식
- 아래 함수에 예측값(Yi) 과 실제값(ti) 에 1을 대입하면, 수식은 0에 수렴하게 됨
- 아래 함수에 예측값(Yi =0)과 실제값(ti = 1)을 대입한다면, 수식은 양의 무한대가 됨
- 따라서 이진 분류에 적합하다고 합니다 :)

▷ keras에서 지원하는 이항 교차 엔트로피
tf.keras.losses.BinaryCrossentropy( from_logits=False, label_smoothing=0, reduction="auto", name="binary_crossentropy" )

2. categorical_crossentropy (범주형 교차 엔트로피)
- 출력을 클래스 소속 확률에 대한 예측으로 이해할 수 있는 문제에서 사용 (즉, 레이블 (y) 클래스가 2개 이상일 경우 사용 즉, 멀티클래스 분류에 사용됨)
- 활성화 함수 : softmax (모든 벡터 요소의 값은 0과 1사이의 값이 나오고, 모든 합이 1이 됨)
- 라벨이 (0,0,1,0,0) , (0,1,0,0,0) 과 같이 one-hot encoding 된 형태로 제공될 때 사용 가능
- 수식
- 아래 수식에서 C 는 클래스의 개수
- 실제값과 예측값이 모두 동일하게 될 경우 손실함수의 값은 0이 나옴
- 실제값과 예측값이 다를 경우 수식에 대입하면 양의 무한대로 발산

▷ keras에서 지원하는 범주형 교차 엔트로피
tf.keras.losses.CategoricalCrossentropy( from_logits=False, label_smoothing=0, reduction="auto", name="categorical_crossentropy", )3. sparse_categorical_crossentropy
tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1)- 범주형 교차 엔트로피와 동일하게 멀티 클래스 분류에 사용
- one-hot encoding 된 상태일 필요 없이 정수 인코딩 된 상태에서 수행 가능
- 라벨이 (1,2,3,4) 이런식으로 정수형태일때 사용!
4. 평균 제곱 오차 손실 (means squared error, MSE)
- 신경망의 출력(^y)과 타겟(y)이 연속값인 회귀 문제에서 널리 사용하는 손실함수
- 회귀문제에 사용될 수 있는 다른 손실 함수
- 평균 절댓값 오차 (Mean absolute error, MAE)
- 평균 제곱근 오차 (Root mean squared error, RMSE)
- 회귀문제에 사용될 수 있는 다른 손실 함수
- 예측과 타겟값의 차이를 제곱하여 평균한 값 (모두 실숫값으로 계산)
- MSE가 크다는 것은 평균 사이에 차이가 크다는 뜻 / MSE가 작다는 것은 데이터와 평균사이의 차이가 작다는 뜻
- 즉, MSE는 데이터가 평균으로부터 얼마나 떨어져있나를 보여주는 손실함수
- 연속형 데이터를 사용할 때 주로 사용 (주식 가격 예측 등)
▷ keras 에서 지원하는 MSE
keras.losses.mean_squared_error(y_true, y_pred)https://www.tensorflow.org/api_docs/python/tf/keras/metrics/mean_squared_error?hl=ko
평가지표(Metric) 이란?
- Metric는 척도, 평가지표 혹은 측정항목이라고도 불린다.
- Metric은 모델의 성능을 평가하는데 사용되는 함수이다.
- Metric 함수는 모델이 컴파일 될 때 metrics 매개변수를 통해 공급된다.
- 검증셋과 연관. 훈련 과정을 모니터링하는데 사용.
- (평가지표로 어떤 것을 사용하더라도 모델 가중치의 업데이트에는 영향을 미치지 않는다)
학습곡선을 그릴 때 손실함수와 평가지표(Metric)를 에포크(epoch)마다 계산한 것을 그려주는데, 손실함수의 추이와 평가지표의 추이를 비교해보면서 모델이 과대적합(overfit) 또는 과소적합(underfit)되고 있는지 여부를 확인할 수 있다.
loss 와 metric의 차이
| loss: 손실함수. 훈련셋과 연관. 훈련에 사용. |
| metric: 평가지표. 검증셋과 연관. 훈련 과정을 모니터링하는데 사용. (모델의 가중치의 업데이트에는 영향을 미치지 않는다.) |
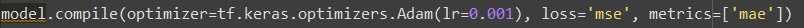
우리는 케라스를 이용하여 모델을 설계 할 때 위와 같은 형태의 코드를 볼 수 있다. 코드를 설명해보자면,
여기서 loss는 손실함수를 의미한다. 모델을 훈련시킬때 이 손실 함수를 최소로 만들어주는 가중치들을 찾는 것을 목표로 한다. 위 예에서는 손실함수로 MSE(mean squared error)를 사용하였다. 손실함수로 MSE만 사용할 수 있는 것이 아니고, 위에서 설명했던 MAE(mean absolute error), hinge, categorical crossentropy, sparse categorical crossentropy, binary crossentropy 등도 사용할 수 있다. 여러 손실 함수 중에서 자신이 훈련시키는 모델에 적합한 손실함수를 선택해주면 된다. 예를 들어, 10개의 클래스를 분류할 수 있는 분류기를 훈련시키는 경우에는 손실함수로 sparse categorical crossentropy를 사용할 수 있다.
반면 metric은 평가지표이다. 검증셋에서 훈련된 모델의 성능을 평가할 때 어떤 평가지표로 평가할지를 결정해줍니다. 학습곡선을 그릴 때 손실함수와 평가지표를 에포크(epoch)마다 계산한 것을 그려주는데, 손실함수의 추이와 평가지표의 추이를 비교해보면서 모델이 과대적합(overfit) 또는 과소적합(underfit)되고 있는지 여부를 확인할 수 있다. 위 예에서는 평가지표로 MAE를 사용했다. 중요한 것은 평가지표로 어떤 것을 사용하더라도 모델 가중치의 업데이트에는 영향을 미치지 않는다는 사실이다.
손실함수(Loss Function)와 평가지표(metric) 커스텀하기
나만의 Loss Function 정의
먼저, 함수형으로 Loss Function을 정의해야하는데, 미분 가능한 Loss Function 이어야 한다. 그렇지 않다면 나중에 Model을 compile 할 때 에러가 나게 된다. 그리고 인자로는 실제값인 y_true와 예측 값인 y_pred을 받게 된다.
활용 예제
from keras import backend as K
# 손실함수 정의
def my_loss(y_true, y_pred):
# 내가 정의한 손실 함수
y_true = y_true ** 2
y_pred = y_pred ** 2
loss = K.mean(K.abs(y_true - y_pred) + K.square(y_true - y_pred))
return loss
위에서는 y_true와 y_pred의 오차율에 대한 absolute 값과 오차 제곱 값을 더한 이에 대한 평균 값을 손실로 return 해주는 예제이다.
나만의 Metric 정의
때론, default로 제공되는 metric 외에 나만의 metric으로 모델이 잘 평가 되고 있는지 확인하고 싶을 수 있다.
활용 예제
# metric 정의
def my_metric(y_true, y_pred):
return K.mean(K.abs(y_true_f - y_pred_f)) * 1000
우선, 내가 평가하고 싶은 metric을 함수형으로 만들어 놓는다.
저는 Mean Absolute Error metric에 1000을 곱해주었는데, 이유는 전처리 진행시 모든 값을 1000으로 나누어 주었기 때문이다. 따라서 매 epoch 마다 print 되는 결과값이 실제 값과 차이가 있기 때문에 metric을 정의해주면 모니터링하기 훨씬 수월하다.
Model 에 적용
def my_model():
model = Sequential()
model.add(Dense(units=100, activation='relu'))
model.add(Dense(units=50, activation='relu'))
model.add(Dense(units=10, activation='relu'))
model.add(Dense(units=4, activation='relu'))
return model
# model을 생성합니다
model = my_model()
# model을 compile 합니다. loss와 metric에는 내가 만든 함수를 대입합니다
model.compile(optimizer='adam', loss=my_loss, metrics=[my_metric])
이렇게 매우 간단하게 커스텀해서 loss와 metric을 측정할 수 있다. 여러 metric을 만들어서 매 epoch 마다 동시에 모니터링 해 볼 수 있다.
Reference
- 텐서플로우 손실함수 공식 문서
www.tensorflow.org/api_docs/python/tf/keras/losses
- 텐서플로우 Metrics(척도) 공식 문서
https://www.tensorflow.org/api_docs/python/tf/keras/metrics
- 케라스 Metrics 공식 문서
- 손실함수와 평가지표 설계하기
https://teddylee777.github.io/tensorflow/keras-metic-%EC%BB%A4%EC%8A%A4%ED%85%80
- 손실함수
https://didu-story.tistory.com/27
- 손실함수와 평가지표의 차이
'공부정리 > 모두의 딥러닝 (교재 정리)' 카테고리의 다른 글
| [deeplearning] 모델 설계하기 (1) (0) | 2022.05.16 |
|---|---|
| [deeplearning] 신경망의 이해 - 신경망에서 딥러닝으로 (0) | 2022.05.02 |
| [deeplearning] 신경망의 이해 - 오차 역전파 (0) | 2022.04.29 |
| [deeplearning] 신경망의 이해 - 퍼셉트론, 다층 퍼셉트론 (0) | 2022.04.29 |
| [deeplearning] 딥러닝의 동작 원리 - 로지스틱 회귀 (0) | 2022.04.14 |