728x90
반응형
해당 게시물은 '박조은'강사님의 인프런 강의, [NLP] IMDB 영화리뷰 감정 분석을 통한 파이썬 텍스트 분석과 자연어 처리를 정리한 게시글입니다.

pre-requires

평가 과정에서는 ROC 커프 이용

x train 행렬 데이터
y train 벡터 데이터
랜덤 포레스트 기본적인 구성
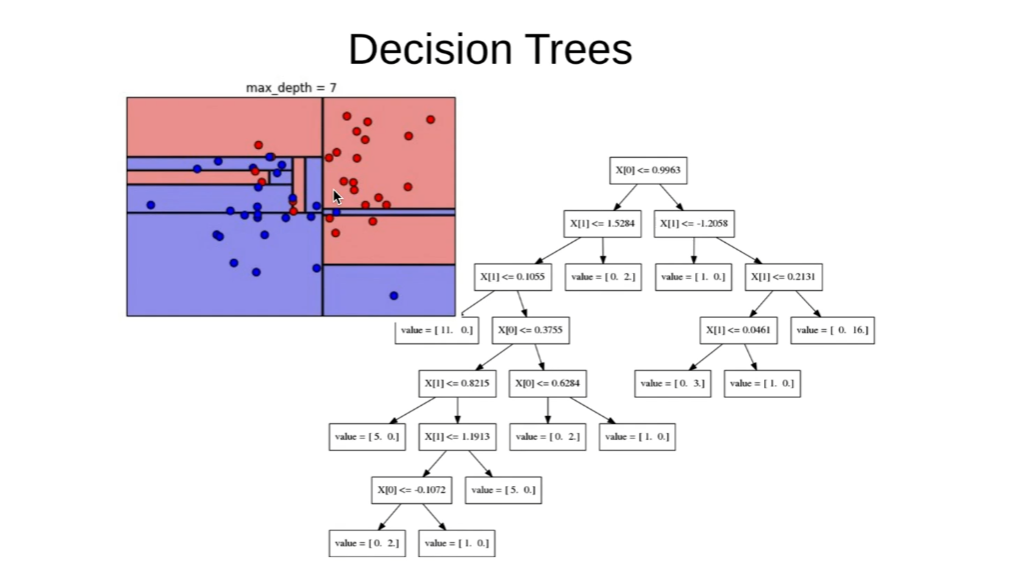

랜덤 포레스트
- 랜덤 포레스트의 가장 핵심적인 특징은 임의성(randomness)에 의해 서로 조금씩 다른 특성을 갖는 트리들로 구성된다는 점이다.
- 이 특징은 각 트리들의 예측(prediction)들이 비상관화(decorrelation) 되게하며, 결과적으로 일반화(generalization) 성능을 향상시킨다.
- 또한, 임의화(randomization)는 포레스트가 노이즈가 포함된 데이터에 대해서도 강하게 만들어 준다.

n_estimators = 100 # 숫자를 크게 지정할 수록 좋은 성능 n_jobs = -1 # 내 장비의 CPU 코어를 모두 사용random_state=2018 # 랜덤포레스트의 스코어를 고정
- 데이터를 학습


교차검증방법을 이용해서 모델 평가하기
- 예측

테스트 데이터 확인 후 벡터화하기

단어 확인하기

캐글 제출을 위해 예측결과 저장

index=False # 인덱스는 저장하지 않도록 한다.quoting=3 # CSV 파일을 불러왔을 때와 동일한 파일로 저장이 되도록sentiment를 통해 긍정, 부정 알아보기

Train, Test의 감정분류 결과 값 비교

첫 번째 제출을 할 준비가 되었다. 리뷰를 다르게 정리하거나 'Bag of Words' 표현을 위해 다른 수의 어휘 단어를 선택하거나 포터 스테밍 등을 시도해 볼 수 있다. 다른 데이터세트로 NLP를 시도해 보려면 로튼 토마토(Rotten Tomatoes)를 해보는 것도 좋다.
728x90
반응형
'공부정리 > NLP' 카테고리의 다른 글
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 2 - (2) Gensim을 통해 벡터화, t-SNE로 시각화하기 - 강의 정리 (0) | 2022.08.29 |
|---|---|
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 2 - (1) 딥러닝 기법 Word2Vec 소개 - 강의 정리 (0) | 2022.08.29 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (3) CountVectorizer 로 텍스트 데이터 벡터화 - 강의 정리 (0) | 2022.08.29 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (2) 데이터 정제하기 (BeautifulSoup, re, NLTK) - 강의 정리 (0) | 2022.08.18 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (1) 데이터 확인하기 - 강의 정리 (0) | 2022.08.18 |