해당 게시물은 '박조은'강사님의 인프런 강의, [NLP] IMDB 영화리뷰 감정 분석을 통한 파이썬 텍스트 분석과 자연어 처리를 정리한 게시글입니다.

Bag of Words Meets Bags of Popcorn
튜토리얼 파트 2 Word Vectors
- 딥러닝 기법인 Word2Vec을 통해 단어를 벡터화 해본다.
- t-SNE를 통해 벡터화 한 데이터를 시각화 해본다.
- 딥러닝과 지도학습의 랜덤포레스트를 사용하는 하이브리드 방식을 사용한다.
Word2Vec(Word Embedding to Vector)
컴퓨터는 숫자만 인식할 수 있고 한글, 이미지는 바이너리 코드로 저장 된다. 튜토리얼 파트1에서는 Bag of Word라는 개념을 사용해서 문자를 벡터화 하여 머신러닝 알고리즘이 이해할 수 있도록 벡터화 해주는 작업을 하였다.
- one hot encoding(예 [0000001000]) 혹은 Bag of Word에서 vector size가 매우 크고 sparse 하므로 neural net 성능이 잘 나오지 않는다.
- 주위 단어가 비슷하면 해당 단어의 의미는 유사하다 라는 아이디어
- 단어를 트레이닝 시킬 때 주위 단어를 label로 매치하여 최적화
- 단어를 의미를 내포한 dense vector로 매칭 시키는 것
- Word2Vec은 분산 된 텍스트 표현을 사용하여 개념 간 유사성을 본다. 예를 들어, 파리와 프랑스가 베를린과 독일이 (수도와 나라) 같은 방식으로 관련되어 있음을 이해한다.

워드 투 벡은 벡터화 했을 때 단어간의 의미를 잃지 않음
- 단어의 임베딩과정을 실시간으로 시각화 : word embedding visual inspector
wevi
Training data (context|target): Presets: Update and Restart Update Learning Rate Next 20 100 500 PCA
ronxin.github.io
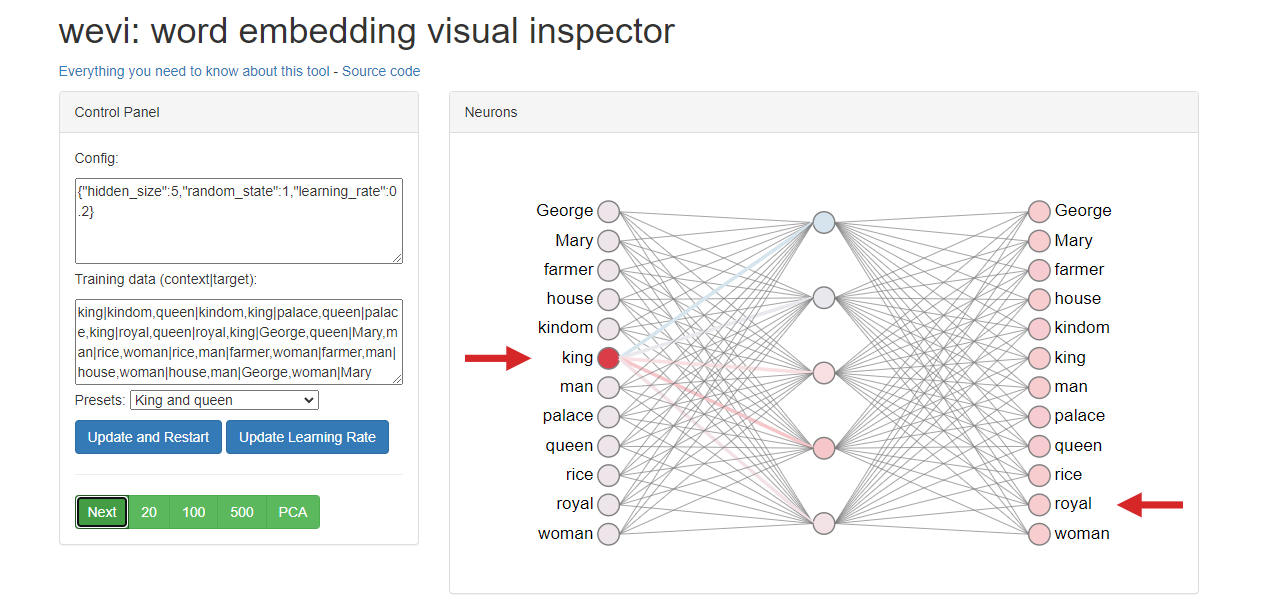


이런 식으로 학습 과정과 결과를 볼 수 있다.
킹- 퀸, 맨- 우먼 거리가 비슷함을 볼 수 있다.
Word2Vec은 두가지 기법으로 나뉜다.

- CBOW
- Skip-gram
- CBOW와 Skip-Gram기법이 있다.
- CBOW(continuous bag-of-words)는 전체 텍스트로 하나의 단어를 예측하기 때문에 작은 데이터셋일 수록 유리하다.
- 아래 예제에서 __ 에 들어갈 단어를 예측한다.
- 1) __가 맛있다. 2) __를 타는 것이 재미있다. 3) 평소보다 두 __로 많이 먹어서 __가 아프다.
- Skip-Gram은 타겟 단어들로부터 원본 단어를 역으로 예측하는 것이다. CBOW와는 반대로 컨텍스트-타겟 쌍을 새로운 발견으로 처리하고 큰 규모의 데이터셋을 가질 때 유리하다.
- 배라는 단어 주변에 올 수 있는 단어를 예측한다.
- 1) *배*가 맛있다. 2) *배*를 타는 것이 재미있다. 3) 평소보다 두 *배*로 많이 먹어서 *배*가 아프다.
출처 : https://arxiv.org/pdf/1301.3781.pdf Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013.
Word2Vec 참고자료
- word2vec 모델 · 텐서플로우 문서 한글 번역본
- Word2Vec으로 문장 분류하기 · ratsgo's blog
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
- CS224n: Natural Language Processing with Deep Learning
- Word2Vec Tutorial - The Skip-Gram Model · Chris McCormick
Gensim - 파이썬으로 워드 투 벡터를 구현
- gensim: models.word2vec – Deep learning with word2vec
- gensim: Tutorials
- 한국어와 NLTK, Gensim의 만남 - PyCon Korea 2015


딜레미터 - 탭
- 데이터 확인


클래스를 만들어서 지속적으로 사용할 내용이다.
클래스 안에 있는 코드의 내용은 데이터 전처리 포스트에서 자세하게 다루고있다.
클래스 코드 확인하기
import re
import nltk
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from nltk.stem.snowball import SnowballStemmer
from multiprocessing import Pool
class KaggleWord2VecUtility(object):
@staticmethod
def review_to_wordlist(review, remove_stopwords=False):
# 1. HTML 제거
review_text = BeautifulSoup(review, "html.parser").get_text()
# 2. 특수문자를 공백으로 바꿔줌
review_text = re.sub('[^a-zA-Z]', ' ', review_text)
# 3. 소문자로 변환 후 나눈다.
words = review_text.lower().split()
# 4. 불용어 제거
if remove_stopwords:
stops = set(stopwords.words('english'))
words = [w for w in words if not w in stops]
# 5. 어간추출
stemmer = SnowballStemmer('english')
words = [stemmer.stem(w) for w in words]
# 6. 리스트 형태로 반환
return(words)
@staticmethod
def review_to_join_words( review, remove_stopwords=False ):
words = KaggleWord2VecUtility.review_to_wordlist(\
review, remove_stopwords=False)
join_words = ' '.join(words)
return join_words
@staticmethod
def review_to_sentences( review, remove_stopwords=False ):
# punkt tokenizer를 로드한다.
"""
이 때, pickle을 사용하는데
pickle을 통해 값을 저장하면 원래 변수에 연결 된 참조값 역시 저장된다.
저장된 pickle을 다시 읽으면 변수에 연결되었던
모든 레퍼런스가 계속 참조 상태를 유지한다.
"""
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
# 1. nltk tokenizer를 사용해서 단어로 토큰화 하고 공백 등을 제거한다.
raw_sentences = tokenizer.tokenize(review.strip())
# 2. 각 문장을 순회한다.
sentences = []
for raw_sentence in raw_sentences:
# 비어있다면 skip
if len(raw_sentence) > 0:
# 태그제거, 알파벳문자가 아닌 것은 공백으로 치환, 불용어제거
sentences.append(\
KaggleWord2VecUtility.review_to_wordlist(\
raw_sentence, remove_stopwords))
return sentences
# 참고 : https://gist.github.com/yong27/7869662
# http://www.racketracer.com/2016/07/06/pandas-in-parallel/
# 속도 개선을 위해 멀티 스레드로 작업하도록
@staticmethod
def _apply_df(args):
df, func, kwargs = args
return df.apply(func, **kwargs)
@staticmethod
def apply_by_multiprocessing(df, func, **kwargs):
# 키워드 항목 중 workers 파라메터를 꺼냄
workers = kwargs.pop('workers')
# 위에서 가져온 workers 수로 프로세스 풀을 정의
pool = Pool(processes=workers)
# 실행할 함수와 데이터프레임을 워커의 수 만큼 나눠 작업
result = pool.map(KaggleWord2VecUtility._apply_df, [(d, func, kwargs)
for d in np.array_split(df, workers)])
pool.close()
# 작업 결과를 합쳐서 반환
return pd.concat(result)