728x90
반응형
https://sillon-coding.tistory.com/302
[Python] 네이버 뉴스 기사 웹 크롤링 - 매크로
해당 사이트를 참고하여 게시글을 작성하였습니다. 1단계. 원하는 웹 페이지의 html문서를 싹 긁어온다. 2단계. 긁어온 html 문서를 파싱(Parsing)한다. 3단계. 파싱한 html 문서에서 원하는 것을 골
sillon-coding.tistory.com

스포를 조금 하자면... 해결하지 못했습니다! 그 이유는 HTML 태그 일부 출력이 되지 않기 때문입니다.
그 과정을 포스팅 해보겠습니다..^^
from bs4 import BeautifulSoup
import urllib.request as req # 특정 웹사이트로 접속하기 위해
url = "https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
print(soup)네이버 뉴스 정치 부분에서 html 코드를 추출해봅시다
출력 결과는 HTML 태그 전체가 추출됩니다.
저는 밑에 있는 기사만 추출할거기때문에 일단 거기에 대한 내용이 있는 태그를 추출해봅시다
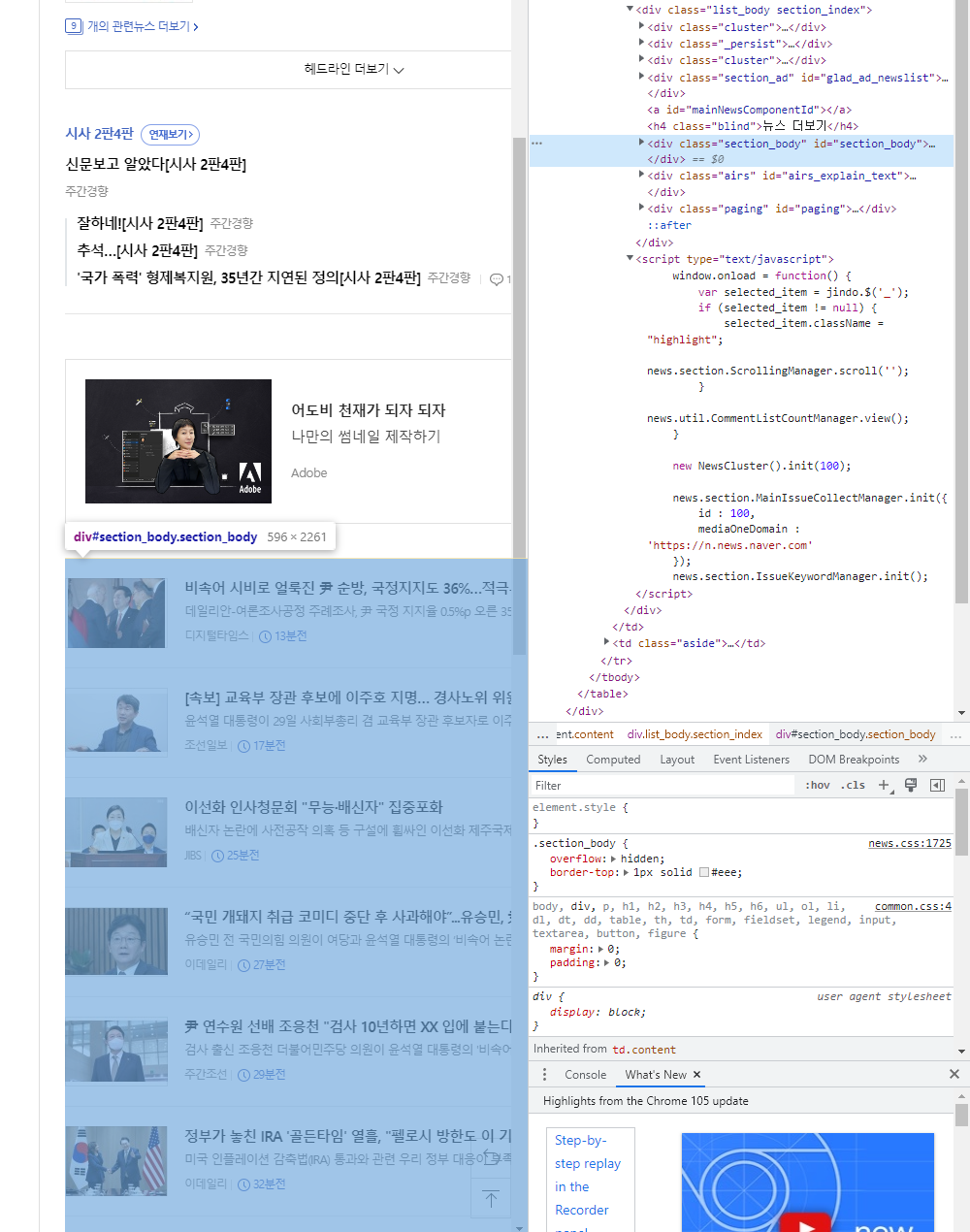
저는 여기서 위의 헤드라인 기사가 아닌 아래부분의 기사를 추출할 것입니다..
태그를 살펴보면 아래와 같습니다.
from bs4 import BeautifulSoup
import urllib.request as req # 특정 웹사이트로 접속하기 위해
url = "https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=100"
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("div",{"class":"section_body"})
print(find_tag)아래 기사부터는 왜인지 태그가 출력이 안되는 모습을 볼 수 있었습니다.
그 이유는 저도 모름... 그래서 다른 방법을 찾아봐야할 것 같습니다.

오늘도 해결 실패!
728x90
반응형
'python > 자동화' 카테고리의 다른 글
| [Python] 웹크롤링 - 태그를 이용해서 크롤링하기 - (3) 사전을 Json파일로 저장 (0) | 2023.03.07 |
|---|---|
| [Python] 웹크롤링 - 태그를 이용해서 크롤링하기 - (2) 사전구축 (0) | 2023.03.07 |
| [Python] 웹 자동화 기초 - 경고창 이동, 쿠키, 자바스크립트 코드 실행 (1) | 2022.09.29 |
| [Python] 웹 자동화 기초 - 엘레먼트(클릭, 텍스트, 프레임 이동) (0) | 2022.09.29 |
| [Python] 웹 자동화 기초 - 브라우저 열기, 닫기, 탭 이동 (0) | 2022.09.29 |