728x90
반응형
이전 코드에서 나아가 한국민족대백과사전의 사전을 크롤링을 통해 만들어보겠습니다.
from bs4 import BeautifulSoup
import urllib.request as req
import argparse # 특정 웹사이트로 접속하기 위해
import re
def crawling_list(url):
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("a",{"class":"depth1-title"}) # "div",{"class":"section_body"}
korean_hist = dict()
for i in range(len(find_tag)):
txt = re.sub(r"[^가-힣]","",str(find_tag[i].get_text())) # 특수문자 제거
korean_hist[txt] = []
return korean_hist
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--url", type=str, default='https://encykorea.aks.ac.kr/')
args = parser.parse_args()
korean_hist = crawling_list(args.url)
print(korean_hist)이전 코드에서 특수문자를 제거하는 코드를 더 작성했습니다. ^-^ v

저는 사전을 크롤링을 통해서 구축할 것이기 때문에 해당 태그들을 수집하겠습니다.
<div class="title">가군(加群)</div>그리고 한 페이지만 흭득하는 것이 아니라, 모든 페이지의 내용을 흭득할 것이므로
페이지를 넘겼을때 어떻게 사이트가 이동하는지 확인합니다.
해당 사이트는 이렇게 페이지를 이동할 때마다 "전체/?p=2&" 에서 숫자가 증하나는 것 같습니다.

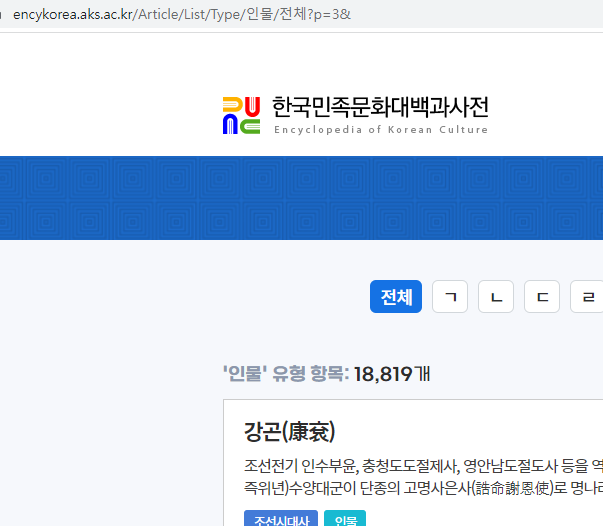
페이지를 벗어나면 이렇게 목록이 안뜨는 것을 볼 수 있습니다.
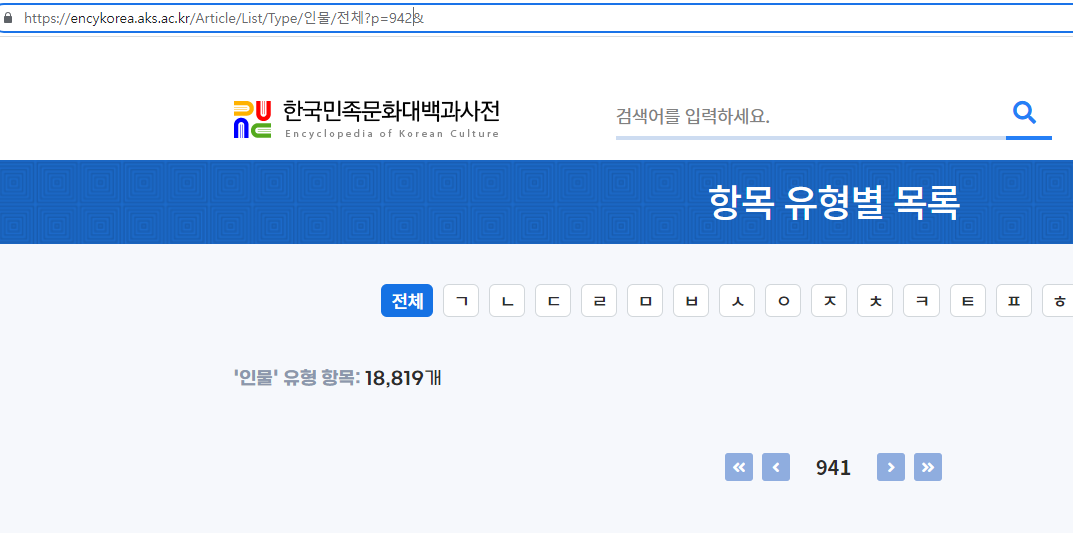
그리고 해당 주소를 이렇게 복사 붙여넣기 해보면
https://encykorea.aks.ac.kr/Article/List/Type/%EC%9D%B8%EB%AC%BC/%EC%A0%84%EC%B2%B4?p=1&저희는 분명 중간에 한글을 넣었는데 이렇게 인코딩 된 주소가 되는 것을 알 수 있습니다.
그래서 파이썬에 주소를 그냥 한글로 입력하면 오류가 발생합니다.
def visit_site(visit_url,word):
word_list = []
i = 1
while True:
url = visit_url + word + "/" + "전체" + "?p=" + str(i) + "&"
print(url)
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("div",{"class":"title"}) # "div",{"class":"section_body"}
for i in range(len(find_tag)):
word_list.append(re.sub(r"[^가-힣a-zA-Z0-9]","",str(find_tag[i].get_text())))
i += 1
break
print(word_list)
return word_listUnicodeEncodeError: 'ascii' codec can't encode characters in position 23-24: ordinal not in range(128) 오류해당 코드로 실행하면 다음과 같은 오류를 볼 수 있습니다.
따라서 주소에 적힌 한글을 인코딩하는 코드를 추가합니다.

def visit_site(visit_url,word):
word_list = []
i = 1
while True:
url = visit_url + word + "/" + "전체" + "?p=" + str(i) + "&"
encoded_url = quote(url, safe=':/?&') # 한글 주소 인코딩
print(encoded_url)
res = req.urlopen(encoded_url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("div",{"class":"title"}) # "div",{"class":"section_body"}
for i in range(len(find_tag)):
word_list.append(re.sub(r"[^가-힣a-zA-Z0-9]","",str(find_tag[i].get_text())))
i += 1
break
print(word_list)
return word_list
이렇게 인코딩이 잘 되는 모습을 볼 수 있습니다 ㅎㅎ
전체 코드
from bs4 import BeautifulSoup
import urllib.request as req
import argparse # 특정 웹사이트로 접속하기 위해
import re
from urllib.parse import quote
def crawling_list(url):
res = req.urlopen(url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("a",{"class":"depth1-title"}) # "div",{"class":"section_body"}
korean_hist = dict()
for i in range(len(find_tag)):
txt = re.sub(r"[^가-힣a-zA-Z0-9]","",str(find_tag[i].get_text())) # 특수문자 제거
korean_hist[txt] = []
return korean_hist
def visit_site(visit_url,word):
word_list = []
idx = 1
while True:
url = visit_url + word + "/" + "전체" + "?p=" + str(idx) + "&"
encoded_url = quote(url, safe=':/?&=') # 한글 주소 인코딩
print(encoded_url)
res = req.urlopen(encoded_url).read()
soup = BeautifulSoup(res, 'html.parser') #분석 용이하게 파싱
find_tag = soup.findAll("div",{"class":"title"}) # "div",{"class":"section_body"}
if find_tag:
for i in range(len(find_tag)):
word_list.append(re.sub(r"[^가-힣a-zA-Z0-9]","",str(find_tag[i].get_text())))
idx += 1
else:
break
print("done")
return word_list
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--url", type=str, default='https://encykorea.aks.ac.kr/')
parser.add_argument("--visit_url", type=str, default='https://encykorea.aks.ac.kr/Article/List/Type/')
args = parser.parse_args()
korean_hist = crawling_list(args.url)
visit_site(args.visit_url,"인물")
for hist in korean_hist:
korean_hist[hist] += visit_site(args.visit_url,hist)
print(hist,"사전의 전체 개수:",len(korean_hist[hist]))728x90
반응형
'python > 자동화' 카테고리의 다른 글
| [Python] 웹크롤링 - 태그를 이용해서 크롤링하기 - (최종) 한국민족문화대백과사전 크롤링하기 (0) | 2023.03.08 |
|---|---|
| [Python] 웹크롤링 - 태그를 이용해서 크롤링하기 - (3) 사전을 Json파일로 저장 (0) | 2023.03.07 |
| [Python] 네이버 뉴스 기사 태그 출력하기 (0) | 2022.09.29 |
| [Python] 웹 자동화 기초 - 경고창 이동, 쿠키, 자바스크립트 코드 실행 (1) | 2022.09.29 |
| [Python] 웹 자동화 기초 - 엘레먼트(클릭, 텍스트, 프레임 이동) (0) | 2022.09.29 |