728x90
반응형
참고 서적
 |
도서명: Data Science from Scratch (밑바닥부터 시작하는 데이터 과학) 저자 : Joel Grus 출판 : 프로그래밍 인사이트 |
Ch 11. machine learning
11.1 modeling
machine learning: 데이터를 통해 모델을 만들고 사용하는 것 (책의 정의)
model: 다양한 변수간의 수학적(혹은 확률적) 관계를 식으로 표현한 것
11.2 What Is Machine Learning?
- supervised learning: 데이터에 정답이 포함
- unsupervised learning: 데이터에 정답이 포함되지 X
- semi-supervised learning: 데이터의일부분에만 정답이 포함되어있음
- online learning: 새로 들어오는 데이터를 통해 모델을 끈임없이 조정
- reinforcement learning: 연속된 예측 뒤 모델이 얼마나 잘 예측했는지 파악
11.3 Regression & Classification
11.3 Evaluation Metrics Of Regression & Classification


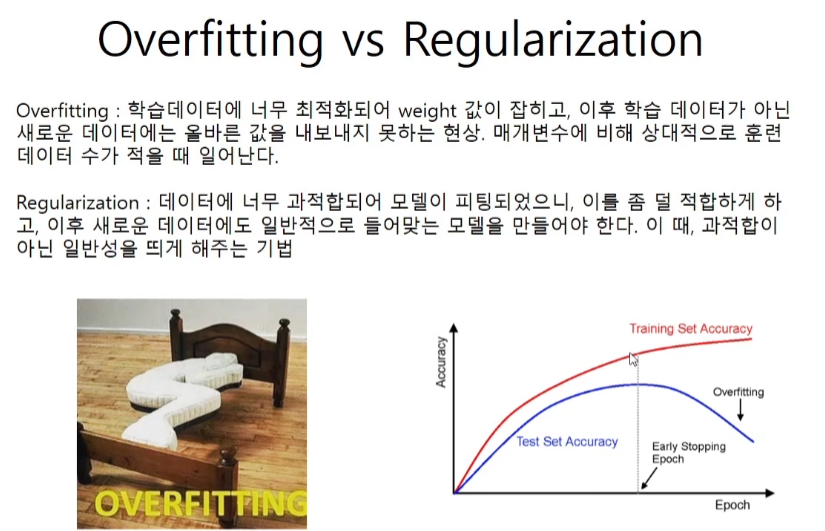
11.4 Overfitting and Underfitting
과적합은 파라미터의 개수가 상대적으로 학습용 데이터의 개수보다 많을 때 일어난다.
Underfitting
모델의 성능이 학습 데이터에서도 좋지 않은 경우를 의미한다. 보통 언더피팅이 발생하면 해당 모델은 문제에서 적합하지 않다는 것을 의미하며, 새로운 모델을 찾아봐야한다.
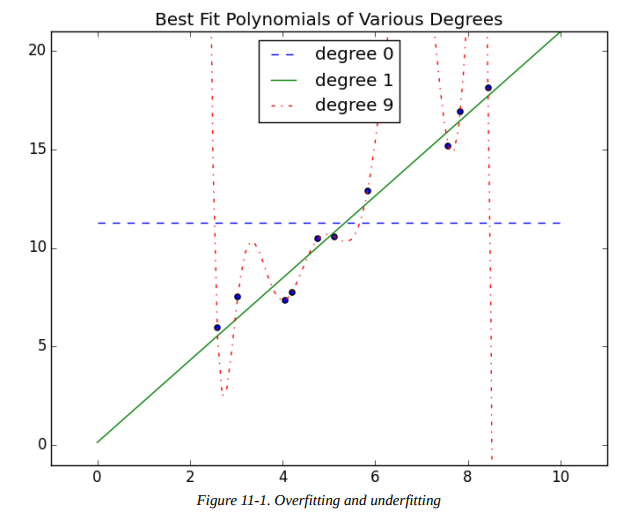
Regularization
NN가 training data의 중요한 정보만 담고, 부수적, 우연적, 특수한 정보를 담지 않게 하는 방법
Weight Decay
penalty는 가중치의 값들의 합이기 때문에 학습시에 penalty를 낮추는 것은 정보를 잃게 만드는 역할을 한다. 다만 덜 중요한(적은) 정보는 결과적으로 더 중요한(많은) 정보에 비해서 더 남지 못하게 될 것이다.

출처: minjung-s.log
728x90
반응형
'공부정리 > Data Science' 카테고리의 다른 글
| [Data Science from Scratch] chapter 12. KNN (0) | 2022.07.28 |
|---|---|
| [Data Science from Scratch] ch.11 additional note (0) | 2022.07.25 |
| [Data Science from Scratch] ch.7, 8 additional note - Gradient Descent without FrameWork! (0) | 2022.07.20 |
| [Data Science from Scratch] Ch 4, 5, 6 additional note (0) | 2022.07.13 |
| [Data Science from Scratch] ch 4. Linear Algebra - (1) Vector (0) | 2022.07.07 |