해당 게시물은 '박조은'강사님의 인프런 강의, [NLP] IMDB 영화리뷰 감정 분석을 통한 파이썬 텍스트 분석과 자연어 처리를 정리한 게시글입니다.

자연어 처리란?
인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고 이를 구현하는 인공지능의 주요 분야 중 하나
자연어 처리는 음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 텍스트 분류 작업(스팸 메일 분류, 뉴스 기사 카테고리 분류), 질의 응답 시스템, 챗봇과 같은 곳에서 사용되는 분야이다.
- 자연어 처리에 대한 자세한 내용
형태소 분석
자연 언어 처리에서 말하는 형태소 분석이란 어떤 대상 어절을 최소의 의미 단위인 '형태소'로 분석하는 것을 의미한다.
형태소 분석 단계에서 문제가 되는 부분은 미등록어, 오탈자, 띄어쓰기 오류 등에 의한 형태소 분석의 오류, 중의성이나 신조어 처리 등이 있는데, 이들은 형태소 분석에 치명적인 약점이라 할 수 있다.
품사 부착
형태소 분석을 통해 나온 결과 중 가장 적합한 형태의 품사를 부착하는 것을 말한다. 보통 태거라고 하는 모듈이 이 기능을 수행한다. 이는 형태소 분석기가 출력한 다양한 분석 결과 중에서 문맥에 적합한 하나의 분석 결과를 선택하는 모듈이라 할 수 있다. 분석 시 문맥 좌우에 위치한 중의성 해소의 힌트가 되는 정보를 이용해서 적합한 분석 결과를 선택한다. 보통 태거는 대규모의 품사부착 말뭉치를 이용해서 구현하는데 은닉 마르코프 모델(HMM)이 널리 사용되고 있다.
'나는'이라는 어절에 대한 형태소 분석이 다음과 같다면
- 나는 → 나(대명사) + 는(조사)
- 나는 → 날(동사) + 는(관형형어미)
다음과 같이 적절한 품사를 부착하는 것이 품사 부착이다.
- 나는 오늘 학교에 갔다' → '나(대명사)+는(조사) 오늘 학교+에 가다+았+다'
- 하늘을 나는 새를 보았다' → '하늘+을 날(동사)+는(관형형어미) 새+를 보다+았+다'
구절 단위 분석
- 구 단위 분석은 명사구, 동사구, 부사구 등의 덩어리를 의미한다.
- 서울시 서초구 서초동에 있는 가장 유명한 회사는 어디인가요? → 서울시 서초구 서초동에 있는 가장 유명한 회사는 어디인가요?
- 이 해결책은 정말이지 여기에는 적합하지 않아 → 이 해결책은 정말이지 여기에는 적합하지 않아
- 절 단위 분석은 중문, 복문 등의 문장을 단문 단위로 분해하는 역할을 수행한다.
- 이 영화는 재미있었는데, 저 영화는 흥미 없었다 → 이 영화는 재미있었는데 , 저 영화는 흥미 없었다
- 어제 내가 본 그 영화는 아주 재미있었다 → 어제 내가 본 그 영화는 아주 재미있었다.
- 나는 오늘 하늘을 나는 새를 보았다 → 나는 오늘 하늘을 나는 새를 보았다
이와 같이, 구 단위 분석을 먼저 수행하고 절 단위 분석을 해서 보다 큰 단위로 만든다. 이러한 분석은 다음 단계인 구문 분석에서의 중의성을 해소하는 데 아주 중요한 역할을 수행한다고 할 수 있다.
(출처 : 위키피디아)
자연어처리(NLP)와 관련 된 캐글 경진대회
- Sentiment Analysis on Movie Reviews | Kaggle
- Toxic Comment Classification Challenge | Kaggle
- Spooky Author Identification | Kaggle
해당 강의를 듣기위해 필요한 패키지
- pandas
- numpy
- scipy
- scikit-learn
- Beautiful Soup
- NLTK
- Cython
- gensim
튜토리얼 개요
파트1
- 초보자를 대상으로 기본 자연어 처리를 다룬다.
파트2, 3
- Word2Vec을 사용하여 모델을 학습시키는 방법과 감정분석에 단어 벡터를 사용하는 방법을 본다.
- 파트3는 레시피를 제공하지 않고 Word2Vec을 사용하는 몇 가지 방법을 실험해 본다.
- 파트3에서는 K-means 알고리즘을 사용해 군집화를 해본다.
- 긍정과 부정 리뷰가 섞여있는 100,000만개의 IMDB 감정분석 데이터 세트를 통해 목표를 달성해 본다.
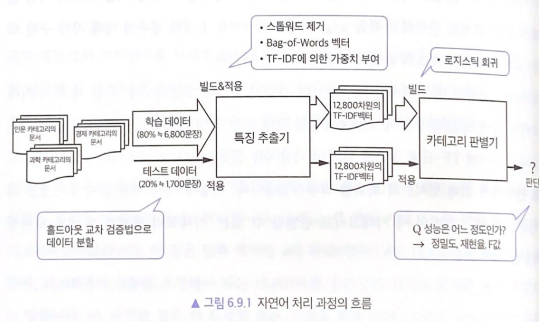
평가 - ROC 커브(Receiver-Operating Characteristic curve)
- TPR(True Positive Rate)과 FPR(False Positive Rate)을 각각 x, y 축으로 놓은 그래프
- 민감도 TPR
- 1인 케이스에 대해 1로 예측한 비율
- 암환자를 진찰해서 암이라고 진단함
- 특이도 FPR
- 0인 케이스에 대해 1로 잘못 예측한 비율
- 암환자가 아닌데 암이라고 진단함
- X, Y가 둘 다 [0, 1] 범위이고 (0, 0)에서 (1, 1)을 잇는 곡선이다.
- ROC 커브의 및 면적이 1에 가까울 수록(왼쪽 꼭지점에 다가갈수록) 좋은 성능
- 참고 :
Use Google's Word2Vec for movie reviews
- 자연어 텍스트를 분석해서 특정단어를 얼마나 사용했는지, 얼마나 자주 사용했는지, 어떤 종류의 텍스트인지 분류하거나 긍정인지 부정인지에 대한 감정분석, 그리고 어떤 내용인지 요약하는 정보를 얻을 수 있다.
- 감정분석은 머신러닝(기계학습)에서 어려운 주제로 풍자, 애매모호한 말, 반어법, 언어 유희로 표현을 하는데 이는 사람과 컴퓨터에게 모두 오해의 소지가 있다. 여기에서는 Word2Vec을 통한 감정분석을 해보는 튜토리얼을 해본다.
- Google의 Word2Vec은 단어의 의미와 관계를 이해하는 데 도움
- 상당수의 NLP기능은 nltk모듈에 구현되어 있는데 이 모듈은 코퍼스, 함수와 알고리즘으로 구성되어 있다.
- 단어 임베딩 모형 테스트 : Korean Word2Vec
BOW(bag of words)
- 가장 간단하지만 효과적이라 널리쓰이는 방법
- 장, 문단, 문장, 서식과 같은 입력 텍스트의 구조를 제외하고 각 단어가 이 말뭉치에 얼마나 많이 나타나는지만 헤아린다.
- 구조와 상관없이 단어의 출현횟수만 세기 때문에 텍스트를 담는 가방(bag)으로 생각할 수 있다.
- BOW는 단어의 순서가 완전히 무시 된다는 단점이 있다. 예를 들어 의미가 완전히 반대인 두 문장이 있다고 하다.
- it's bad, not good at all.
- it's good, not bad at all.
- 위 두 문장은 의미가 전혀 반대지만 완전히 동일하게 반환된다.
- 이를 보완하기 위해 n-gram을 사용하는 데 BOW는 하나의 토큰을 사용하지만 n-gram은 n개의 토큰을 사용할 수 있도록 한다.
- Bag-of-words model - Wikipedia
Bag-of-words model - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Representation of a text as the bag of its words The bag-of-words model is a simplifying representation used in natural language processing and information retrieval (IR). In this mode
en.wikipedia.org
왜 이 튜토리얼에서는 Bag of Words가 더 좋은 결과를 가져올까?
벡터를 평균화하고 centroids를 사용하면 단어 순서가 어긋나며 Bag of Words 개념과 매우 비슷하다. 성능이 (표준 오차의 범위 내에서) 비슷하기 때문에 튜토리얼 1, 2, 3이 동등한 결과를 가져온다.
첫째, Word2Vec을 더 많은 텍스트로 학습시키면 성능이 좋아진다. Google의 결과는 10 억 단어가 넘는 코퍼스에서 배운 단어 벡터를 기반으로 한다. 학습 레이블이 있거나 레이블이 없는 학습 세트는 단지 대략 천팔백만 단어 정도다. 편의상 Word2Vec은 Google의 원래 C도구에서 출력되는 사전 학습 된 모델을 로드하는 기능을 제공하기 때문에 C로 모델을 학습 한 다음 Python으로 가져올 수도 있다.
둘째, 출판 된 자료들에서 분산 워드 벡터 기술은 Bag of Words 모델보다 우수한 것으로 나타났다. 이 논문에서는 IMDB 데이터 집합에 단락 벡터 (Paragraph Vector)라는 알고리즘을 사용하여 현재까지의 최첨단 결과 중 일부를 생성한다. 단락 벡터는 단어 순서 정보를 보존하는 반면 벡터 평균화 및 클러스터링은 단어 순서를 잃어 버리기 때문에 여기에서 시도하는 방식보다 부분적으로 더 좋다.
'공부정리 > NLP' 카테고리의 다른 글
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 2 - (1) 딥러닝 기법 Word2Vec 소개 - 강의 정리 (0) | 2022.08.29 |
|---|---|
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (4) 랜덤 포레스트로 영화 감성 예측 평가 ROC / AUC - 강의 정리 (0) | 2022.08.29 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (3) CountVectorizer 로 텍스트 데이터 벡터화 - 강의 정리 (0) | 2022.08.29 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (2) 데이터 정제하기 (BeautifulSoup, re, NLTK) - 강의 정리 (0) | 2022.08.18 |
| [NLP] 캐글 영화 리뷰 분석 튜토리얼 (1) 데이터 확인하기 - 강의 정리 (0) | 2022.08.18 |