728x90
반응형
데이터를 로드하고 전처리해봅시다
사용한 데이터는 네이버 ner 데이터 셋을 이용하였습니다.
데이터셋 출처 -> https://github.com/naver/nlp-challenge
GitHub - naver/nlp-challenge: NLP Shared tasks (NER, SRL) using NSML
NLP Shared tasks (NER, SRL) using NSML. Contribute to naver/nlp-challenge development by creating an account on GitHub.
github.com
해당 데이터셋을 텍스트파일로 바꾸어 사용하였습니다.

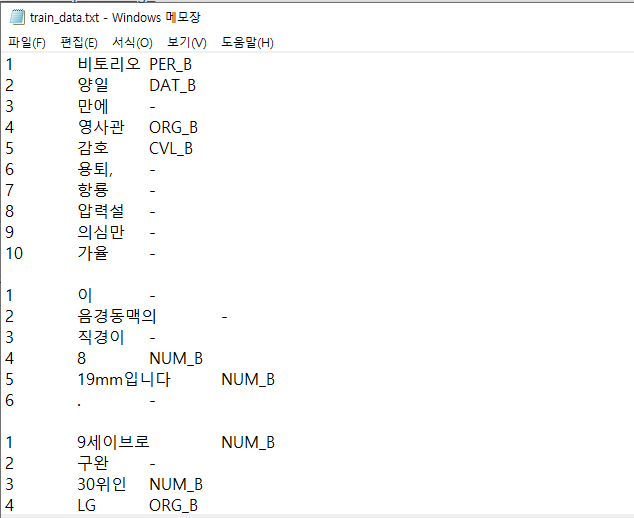
데이터는 이렇게 각 문장의 인덱스와 단어, 개체명 순서로 있습니다.
그럼 데이터를 사용하기 편하도록 전처리 해보겠습니다.
import os
이렇게 파이썬으로 실행해서 봅시다.
원래 주피터 노트북으로 작업했는데 비주얼 스튜디오 코드 환경에서 자꾸 종료되는 현상이 있어, 그냥 파이썬으로 옮겨가 작업하게 되었습니다.
해당 파일을 인덱스,단어,개체명태그로 나누어 단어와 개체명 태그만 따로 리스트에 저장해주었습니다.
tagged_sentences = []
sentences = []
with open("train_data.txt","r") as f:
for line in f:
if len(line) == 0 or line[0] == "\n":
if len(sentences) > 0:
tagged_sentences.append(sentences)
sentence = []
splits = line.rstrip('\n').split('\t')
if len(splits) == 3:
sentences.append([splits[1],splits[-1]])
print(len(tagged_sentences))
print(tagged_sentences[0])전체 코드입니다.
data_load.py
import os
def file_load(file_path):
tagged_sentences = []
sentences = []
with open(file_path,"r") as f:
for line in f:
if len(line) == 0 or line[0] == "\n":
if len(sentences) > 0:
tagged_sentences.append(sentences)
sentences = []
splits = line.rstrip('\n').split('\t')
if len(splits) == 3:
sentences.append([splits[1],splits[-1]])
print(len(tagged_sentences))
print(tagged_sentences[0])
if __name__ == "__main__":
file_path = "train_data.txt"
file_load(file_path)출력결과
[['비토리오', 'PER_B'], ['양일', 'DAT_B'], ['만에', '-'], ['영사관', 'ORG_B'], ['감호', 'CVL_B'], ['용퇴,', '-'], ['항룡', '-'], ['압력설', '-'], ['의심만', '-'], ['가율', '-']]네 이렇게 잘 분리 되었네요
그 다음 단어리스트와 태그리스트 이렇게 따로 모아서 확인도 한번 해보겠습니다.
def tag_split(tagged_sentences):
sentences, ner_tags = [],[]
for tagged_sentence in tagged_sentences:
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence))
ner_tags.append(list(tag_info))
print("단어",sentences[:5])
print("태그",ner_tags[:5])단어 [['비토리오', '양일', '만에', '영사관', '감호', '용퇴,', '항룡', '압력설', '의심만', '가율'], ['이', '음경동맥의', '직경이', '8', '19mm입니다', '.'], ['9세이브로', '구완', '30위인', 'LG', '박찬형은', '평균자책점이', '16.45로', '준수한', '편이지만', '22⅓이닝', '동안', '피홈런이', '31개나', '된다', '.'], ['7승', '25패는', '상트페테르부르크가', '역대', '월드리그에', '출진한', '분별', '최선의', '성적이다', '.'], ['▲', '퍼거슨', '씨족의', '꾀']]
태그 [['PER_B', 'DAT_B', '-', 'ORG_B', 'CVL_B', '-', '-', '-', '-', '-'], ['-', '-', '-', 'NUM_B', 'NUM_B', '-'], ['NUM_B', '-', 'NUM_B', 'ORG_B', 'PER_B', '-', 'NUM_B', '-', '-', 'NUM_B', '-', '-', 'NUM_B', '-', '-'], ['NUM_B', 'NUM_B', 'LOC_B', '-', 'EVT_B', '-', '-', '-', '-', '-'], ['-', 'PER_B', 'CVL_B', '-']]잘 넣어졌네용 ㅎㅎ
그럼 전체 코드를 확인해보겠습니다.
data_load.py
import os
def file_load(file_path):
tagged_sentences = []
sentences = []
with open(file_path,"r") as f:
for line in f:
if len(line) == 0 or line[0] == "\n":
if len(sentences) > 0:
tagged_sentences.append(sentences)
sentences = []
splits = line.rstrip('\n').split('\t')
if len(splits) == 3:
sentences.append([splits[1],splits[-1]])
return tagged_sentences
def tag_split(tagged_sentences):
sentences, ner_tags = [],[]
for tagged_sentence in tagged_sentences:
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence))
ner_tags.append(list(tag_info))
print("단어",sentences[:5])
print("태그",ner_tags[:5])
if __name__ == "__main__":
file_path = "train_data.txt"
tagged_sentences = file_load(file_path)
tag_split(tagged_sentences)728x90
반응형
'Project > 캡스톤디자인2' 카테고리의 다른 글
| [NLP Project] input 값을 넣어 개체명 인식하기 - 오류 해결 (0) | 2022.11.07 |
|---|---|
| [NLP Project] 성능 기록 (0) | 2022.11.06 |
| [NLP Project] 5. 정답 예측하기 (0) | 2022.11.06 |
| [NLP Project] 4. LSTM 모델 구축 (0) | 2022.11.06 |
| [NLP Project] 2. 토큰화 하기 (0) | 2022.11.05 |