728x90
반응형
먼저 main.py를 생성하여 전체적인 실행을 관리할 파일을 만들었다.
data_load.py
import os
# 파일 로드하고 텍스트파일 전처리하기
def file_load(file_path):
tagged_sentences = []
sentences = []
with open(file_path,"r") as f:
for line in f:
if len(line) == 0 or line[0] == "\n":
if len(sentences) > 0:
tagged_sentences.append(sentences)
sentences = []
splits = line.rstrip('\n').split('\t')
if len(splits) == 3:
sentences.append([splits[1],splits[-1]])
return tagged_sentences
# 전처리한 데이터를 바탕으로 단어와 태그 나누기
def tag_split(tagged_sentences):
sentences, ner_tags = [],[]
for tagged_sentence in tagged_sentences:
sentence, tag_info = zip(*tagged_sentence)
sentences.append(list(sentence))
ner_tags.append(list(tag_info))
print("단어",sentences[:5])
print("태그",ner_tags[:5])
return sentences, ner_tags
main.py
from data_load import file_load, tag_split
if __name__ == "__main__":
file_path = "data/train_data.txt"
tagged_sentences = file_load(file_path)
sentences, ner_tags = tag_split(tagged_sentences)
이제 단어를 토큰화하여 빈도수가 높은 상위 단어들을 추출화할 것이다.
tokenization.py
from tensorflow.keras.preprocessing.text import Tokenizer
# 정제 및 빈도수가 높은 상위 단어들만 추출하기 위해 토큰화 작업
def Token(sentences,ner_tags):
max_words = 4000
src_tokenizer = Tokenizer(num_words=max_words,oov_token='-')
src_tokenizer.fit_on_tests(sentences)
tar_tokenizer = Tokenizer()
tar_tokenizer.fit_on_texts(ner_tags)
vocab_size = max_words
tag_size = len(tar_tokenizer.word_index) + 1
print(vocab_size,tag_size)
main.py
from data_load import file_load, tag_split
from tokenization import Token
if __name__ == "__main__":
file_path = "data/train_data.txt"
tagged_sentences = file_load(file_path)
sentences, ner_tags = tag_split(tagged_sentences)
Token(sentences,ner_tags)
print(vocab_size,tag_size) 에 대한 출력 결과
4000 30태그 종류도 궁금해져서 출력해보았다.
print(vocab_size,tag_size,tar_tokenizer.word_index)
4000 30 {'-': 1, 'cvl_b': 2, 'num_b': 3, 'per_b': 4, 'org_b': 5, 'dat_b': 6, 'loc_b': 7, 'trm_b': 8, 'evt_b': 9, 'num_i': 10, 'dat_i': 11, 'anm_b': 12, 'evt_i': 13, 'per_i': 14, 'org_i': 15, 'afw_b': 16, 'cvl_i': 17, 'trm_i': 18, 'tim_b': 19, 'fld_b': 20, 'afw_i': 21, 'tim_i': 22, 'plt_b': 23, 'mat_b': 24, 'loc_i': 25, 'anm_i': 26, 'fld_i': 27, 'mat_i': 28, 'plt_i': 29}
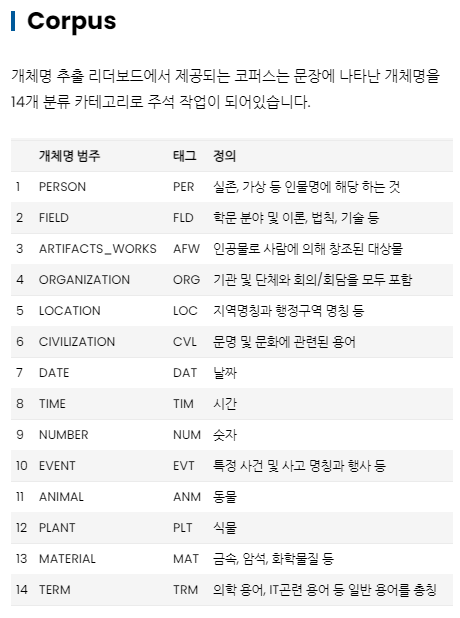
그렇다.. 이건 네이버에서 제공한 태그의 갯수!
원래 14개의 태그가 있지만 자세히 보면 각 태그 * 2 + 1 개임을 알 수 있는데 이 이유는
B는 개체명의 시작 어절, I는 앞의 어절과 연속된 같은 개체명을 의미하고, ‘-‘는 개체명이 부여되지 않는 어절이다.
더보기
아래 “나는 창원대학교에서 열린 대동제를 구경하러 갔다.”라는 예제와 같이 각 행에는 어절로 구분하여 개체명 정보를 담고 있습니다. 개체명 정보는 탭(\t)을 기준으로 첫번째 열은 어절번호, 두번째 열은 어절, 세번째 열은 개체명 레이블입니다. 개체명 레이블은 표에 정의된 것과 같이 14개로 부여됩니다. 단, 여러 어절에 걸쳐 표현된 개체명을 위해 14개의 카테고리 뒤 B/I/-의 추가 정보를 부착하여 표현합니다. 개체명 레이블 정의 및 정책은 다음과 같습니다.
- B는 개체명의 시작 어절, I는 앞의 어절과 연속된 같은 개체명을 의미하고, ‘-‘는 개체명이 부여되지 않는 어절이다.
- B와 I는 14개 분류 카테고리와 조합하여 표현한다. 예) LOC_B, PER_B, LOC_I, PER_I
- 개체명이 시작하는 어절의 레이블은 B와 카테고리의 조합으로 시작한다.
- 어절에 두가지 이상의 개체명이 포함된 경우, 먼저 표현된 개체명만 레이블로 표현한다. 예) “창원대학교(컴퓨터공학과)에서”의 어절은 “창원대학교/LOC_B”와 “컴퓨터공학과/ORG_B” 두개 카테고리를 담고있다. 이런 경우 개체명 레이블은 어절에서 먼저 표현된 “창원대학교”를 기준으로 LOC_B가 된다.
0 나는 -
1 창원대학교에서 LOC_B
2 열린 -
3 대동제를 EVT_B
4 구경하러 -
5 갔다. -
그다음 토큰화된 단어들도 출력해보았다. 총 400,000개를 max로 하여 출력하였으므로
조금 엿보자면
'16만명당': 321249, '12.3명으로': 321250, '10위입니다': 321251, '기획전은': 321252, '고환': 321253, '휴대형멀티미디어플레이어(pmp)': 321254, '조경제의': 321255, '자세': 321256, '안현식▲': 321257, '말라서인지': 321258, '대통밥인': 321259, '문대연은': 321260, '‘하이제’와의': 321261, '“소니가': 321262, 'hd-dvd로': 321263, '출시되기를': 321264, '원했다”면서': 321265, '곤명했지만': 321266, '경찰행정학과는': 321267, '병력하지': 321268, '넣기도': 321269, '사망소식': 321270, '조립에': 321271, '금속판을': 321272, '이파니': 321273, '모시잎차가': 321274, '망치잡이들의': 321275, '캘리컷을': 321276, '10-0(25-18': 321277, '24-20': 321278, '11-17)로': 321279, '열대야에': 321280, '여름날': 321281, '가볍기': 321282, '시정권고는': 321283, '남단부,': 321284, '공능동,': 321285, '뢰치베르크터널': 321286, '최다득점상': 321287, '무상하기를': 321288, '나았을': 321289, '떠나기에는': 321290, '늦어버려서': 321291, '보호센터에서': 321292, '일상생활했습니다': 321293, '이벤트…': 321294, '삭감정책': 321295, '30.2%로': 321296, '◇수원,': 321297, '3년차에': 321298, '체르노프의': 321299, '연련하면서': 321300, '괄약근은': 321301, '치지한': 321302, '김형자는': 321303, '25만달러의': 321304, '초상권을': 321305, '12위(205만3890달러)로': 321306, '자미사들은': 321307, '동부부탄을': 321308, '12승12패로': 321309, '기사회생했지만': 321310, '패자부활전을': 321311, '고개로': 321312, '자봤다는': 321313, '깨어나기가': 321314, '움직임부터': 321315, '30-6으로': 321316, '22연패의': 321317, '2개나': 321318, '질투는': 321319, '혼야': 321320, '만발한': 321321, '따스한': 321322, '집기의': 321323, '보유율이': 321324, '‘월드dab포럼': 321325, '서울총회’를': 321326, '문성민형': 321327, '오리온전기': 321328, '댄스신동(왼쪽),': 321329, '기시다': 321330, '킹메이커와': 321331, '최도영은': 321332, '성인대표팀에': 321333, '탑선하는': 321334, '누렸고': 321335, '천성명은': 321336, '종합체육행사': 321337, '한자일지도': 321338, '만단이': 321339, '본체하는데요': 321340, '정맥염': 321341, '26세이브를': 321342, '문예들,': 321343, '회수되는': 321344, '3만개에': 321345, '산업정책의': 321346, '성식’이다': 321347, '여병을': 321348, '[전자랜드': 321349, '활약장면': 321350, '스타커플은': 321351, '서먹하고,': 321352, '말레이족의': 321353, '쌓아간다': 321354, '미국프로농구(nba)에': 321355, '러더데일은': 321356, '14.9cm,': 321357, '3.2kg으로': 321358, '사우다비가': 321359, '더미가': 321360, '수익률은': 321361, '시니어대표팀은': 321362, '첩보원을': 321363, '여는데': 321364, '제기동에': 321365, '들어오거나': 321366, '들여왔답니다': 321367, '9~3일': 321368, '개념어에': 321369, '혼합하지': 321370, '맥셰인': 321371, 'ces’의': 321372, '연설자로': 321373, '나와,': 321374,이런식으로 토큰화 되어있다.
728x90
반응형
'Project > 캡스톤디자인2' 카테고리의 다른 글
| [NLP Project] input 값을 넣어 개체명 인식하기 - 오류 해결 (0) | 2022.11.07 |
|---|---|
| [NLP Project] 성능 기록 (0) | 2022.11.06 |
| [NLP Project] 5. 정답 예측하기 (0) | 2022.11.06 |
| [NLP Project] 4. LSTM 모델 구축 (0) | 2022.11.06 |
| [NLP Project] 1. 데이터 로드하고 전처리하기 (0) | 2022.11.05 |