728x90
반응형
Linked List
- 연결리스트
- 배열은 순차적으로 연결된 공간에 연속적으로 데이터를 저장
- 연결리스트는 떨어진 공간에서도 사용할 수 있다
- 파이썬에서는 리스트가 연결리스트를 모두 지원


예시
- 파이썬의 기본 자료구조인 리스트(list)
용어
- 노드(Node): 데이터의 저장 단위. 데이터와 포인터로 구성
- 포인터(Pointer): 각 노드 안에서 다음 노드의 주소 정보를 가지고 있는 공간
- head: 연결리스트의 맨 앞 노드
- tail: 연결리스트의 맨 마지막 노드
장단점
장점
- 동적으로 메모리 사용
- 데이터의 재구성 용이
단점
- 특정 인덱스의 데이터에 접근하기 어려움
- 즉, 중간 노드의 탐색이 어려움
- 연결을 위한 포인터와 같은 별도의 공간이 필요함으로 저장 공간 효율이 좋지 않음
- 배열은 인덱스를 통해 데이터에 접근하므로 시간복잡도O(1)을 갖지만, 링크드리스트의 경우 O(n)을 갖는다.
- 연결된 정보를 찾기 위해 주소를 확인하고 다음 데이터를 탐색하는 시간이 있기 떄문에 접근 속도가 느리다.
- 중간 데이터의 삭제 / 수정 / 추가 시, 앞뒤 노드를 재구성해야 하는 추가작업 필요
연습
1. 간단히 구현
파이썬의 클래스를 활용. 각 노드를 객체로 관리한다.
1) 노드 생성
#Node 정의
class Node:
def __init__(self, data, next=None):
#data 만 입력시 next 초기값은 None이다.
self.data = data #다음 데이터 주소 초기값 = None
self.next = next
#Node 생성해보기 (data = 1)
node1 = Node(1)
#Node의 값과 포인터 출력하기
print(node1.data)
print(node1.next)
여기서 next는 다음 노드에 접근하는 방법이다.
예시 ) L.head == a
a.next == b
b.next == c
2) 노드 연결하기
class Node:
def __init__(self,data, next = None):
self.data = data # 다음 데이터 주소 초기값 = None
self.next = next
# Node1 생성해보기(data = 1)
node1 = Node(1)
# Node2 생성해보기
node2 = Node(3)
# Node 연결하기
node1.next = node2
# 가장 맨 앞 Node를 알기 위해 head 지정
head = node1
# Node의 값과 포인터 출력하기
print(node1.data)
print()
print(node1.next.data) # 노드 1의 다음 값(노드2)
print(node2.data) #노드 2의 값
첫번 째 줄에 노드 1의 값인 1이 출력 되었고 세번째 줄, 네번째 줄에는 두번째 노드값이 출력된 것
노드1의 다음 값 = 노드2의 값 이므로 알맞게 출력된 것을 확인할 수 있다.
2. 클래스 이용
연결리스트에서는 리스트의 맨 앞을 가리키는 head가 매우 중요한 것 같다.
1) 원하는 Node에 접근하기 (순차적으로 노드 요소에 접근하는 방법 사용)
pos번째의 node를 가리키고 싶을 때 쓰는 매서드이다.
def getNodeAt(self, pos):
if pos < 0: # pos -1
return None # 추가하려는 노드 앞에 아무것도 없으면 해당 노드를 첫 노드로 만듦
node = self.head # 앞에 노드 있는 경우 head에서부터 pos-1까지 이동
while pos > 0 and node != None: # pos 0되고 node 존재할 경우에 반복
node = node.next # 앞에서부터 pos-1 있는 위치까지 검사(linked list의 단점)
pos -= 1
return node # pos-1에 해당하는 노드 전달단, pos의 예외 범위를 if 로 지정해줘야한다!
2) 리스트를 순회할 때
연결리스트에 들어있는 data를 리스트의 요소로 하나하나 append하고, 최종 리스트를 반환한다.
주의해야할 점은, 리스트 안에 append 되어야 할 것이 node 자체가 아니라 node 안의 data라는 것이다!
def traverse(self):
t_list = []
curr_node = self.head # 첫 노드에 접근
while curr_node != None: # tail이 되면 none이 됨
t_list.append(curr_node.data) # 노드가 아니라 item을 넣음
curr_node = curr_node.next # 다음 노드에 접근
return t_list
3. 노드 추가, 삭제, 수정
1. 노드 추가
1) 맨 앞에 노드를 삽입하기

def addFront(self, data):
new_node = Node(data) # create a new Node
if self.head: # head가 이미 존재하면
new_node.next = self.head # 추가하려는 노드의 next가 예전 head를 가리키도록 하고
self.head = new_node # 새로운 head는 new Node를 가리키도록 한다.
2) 주어진 노드 뒤에 노드 삽입하기

def addAt(self, pos, data): # pos 0, data 10
before = self.getNodeAt(pos - 1) # before은 추가하려는 위치 바로 앞의 노드
if before == None: # 단, 추가하려는 게 첫 노드라면 before은 첫번째 노드
self.head = Node(data, self.head) # 현재 값으로 첫 노드 생성
else: # 아니라면
node = Node(data, before.next) # 추가하려는 노드 뒤
before.next = node # 그리고 before의 next는 node(추가 노드)를 가리키도록 한다.
3) 끝에 노드 삽입하기

def addRear(self, data):
if self.head is None:
self.addFront(data)
else:
temp = self.head
while temp.next: # next가 존재할 때까지
temp = temp.next # 마지막노드까지 이동
temp.next = Node(data, None) # temp(마지막 노드)가 추가하려는 노드를 가리킨다.
이때 연결리스트의 원소 삽입 복잡도는 다음과 같다.
- 맨 앞 삽입 : O(1)
- 중간 삽입 : O(n)
- 맨 끝 삽입 : O(1) (tail 포인터 때문)
2. 노드 삭제
연결리스트의 노드를 삭제하는 종류에는 세 가지가 있다.
- head 삭제
- tail 삭제
- 중간 노드 삭제
1) head 삭제
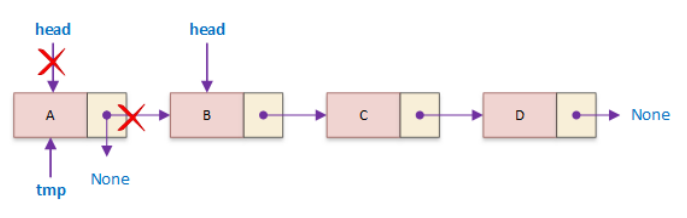
def deleteFront(self):
temp = self.head # temp가 첫번째 노드를 가리킨다.
if self.head:
self.head = self.head.next # 이제 head는 2번째 노드를 가리킨다.
temp.next = None # 2번째 노드를 가리키던 temp.next를 끊어버린다.
return temp # 삭제한 첫 번째 노드의 데이터 값은 보존된다.
2) 끝 노드 삭제하기

def deleteRear(self):
temp = self.head # temp가 첫 번째 노드를 가리킨다.
if self.head:
if self.head.next is None: # 노드가 1개만 있으면 그냥 head가 아무것도 안가리키게 한다.
self.head = None
else: # 노드가 2개 이상
while temp.next.next: # 끝에서 2개의 노드가 남을때까지
temp = temp.next # temp를 이동한다.
second_last = temp # 끝에서 2번째 노드
temp = temp.next # temp는 끝 노드
second_last.next = None # 끝에서 2번째 노드가 아무것도 안 가리킨다.
return temp # 삭제한 끝 노드의 데이터 값은 보존된다.
3) pos 위치의 노드 삭제하기
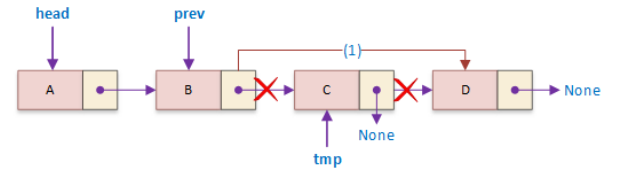
- pos = 0 맨 앞은 그냥 deleteFront()
- pos = self.getSize()이면 deleteRear()
- pos가 엉뚱한 경우 또는 self.head == None에는 그냥 None 반환
- 나머지의 경우 pos 앞 노드에 접근하고 끊어버리기
def deleteAt(self, pos):
temp = Node()
if (self.isEmpty()) or (pos > self.getSize()):
temp = None # 노드가 없거나 해당 pos가 존재하지 않는 경우
elif pos == 0: # 맨 앞 노드 삭제하는 경우
temp = self.deleteFront()
elif pos == self.getSize(): # (List의 크기 = 맨 마지막 노드)를 삭제
temp = self.deleteRear()
else:
prev = self.getNodeAt(pos - 1)
temp = prev.next # 삭제하려는 노드 앞이 가리키는 노드(삭제하려는 노드)를 잠깐 담고
prev.next = temp.next # 예를 들어 1, 2, 3중 2를 지우려고 한다면 1이 3을 가리키도록 한다.
temp.next = None # 그리고 삭제하려는 노드를 3에서 끊어낸다.
return temp # 삭제 노드 반환
3. 노드 참조, 수정
특정 값을 가지는 노드 찾기
- 데이터 가져오기: getDataAt 함수 이용, pos에 위치하는 데이터를 가져온다.
- 데이터 수정하기: replaceDataAt 함수 이용, pos에 위치하는 데이터를 가져와서 수정한다.
def getDataAt(self, pos):
node = self.getNodeAt(pos)
if node == None:
return None
else:
return node.data
def replaceDataAt(self, pos, data):
node = self.getNodeAt(pos)
if node != None:
node.data = data
- 추가적인 내용(향후 수정 예정)
더보기
- 나머지
# -> mention the return type def isEmpty(self) -> bool: return self.head == None def clear(self): self.head = None def getSize(self): node = self.head count = 0 while node is not None: node = node.getNext() count += 1 return count def findData(self, val): node = self.head while node is not None: if node.data == val: return node.data node = node.next return node def reverseList(self): prev = None temp = self.head while temp: next_node = temp.next temp.next = prev prev = temp temp = next_node self.head = prev
헷갈리는 코드 정리
- 끝에서 2개의 노드가 남을때까지
- temp는 끝에서 2번째의 노드
while temp.next.next: temp = temp.next
- 끝에서 1개의 노드만 남을때까지
- temp는 끝 노드
while temp.next: temp = temp.next
reference
- 이미지 1 https://medium.com/tanay-toshniwal/linked-list-introduction-662f7973dee5
728x90
반응형
'python > 자료구조 & 알고리즘' 카테고리의 다른 글
| [자료구조] 우선순위 큐(Priority Queue)와 힙(Heap) / Python 파이썬 (0) | 2022.07.29 |
|---|---|
| [자료구조] 트리 Tree / Python 파이썬 (0) | 2022.05.25 |
| [자료구조] 스택, 큐, 재귀함수 / Python 파이썬 (0) | 2022.05.06 |
| [알고리즘] 정렬 알고리즘 / Python 파이썬 (0) | 2022.05.03 |
| [알고리즘] 8-Puzzle (8 퍼즐) BFS, DFS 구현 / Python 파이썬 (0) | 2022.04.28 |